 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Quantization Improves Generalization: NTK of Binary Weight Neural Networks
Paper and Code
Jun 13, 2022
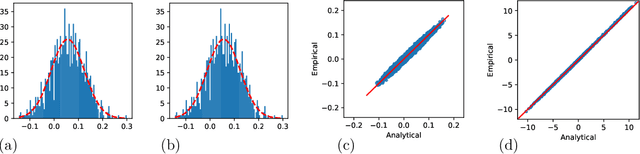

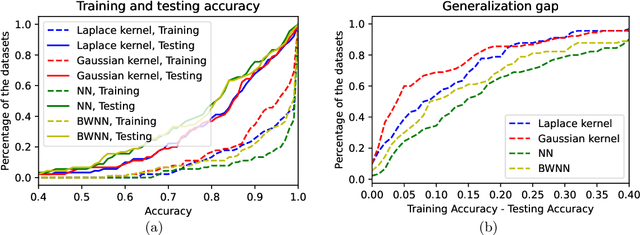
Quantized neural networks have drawn a lot of attention as they reduce the space and computational complexity during the inference. Moreover, there has been folklore that quantization acts as an implicit regularizer and thus can improve the generalizability of neural networks, yet no existing work formalizes this interesting folklore. In this paper, we take the binary weights in a neural network as random variables under stochastic rounding, and study the distribution propagation over different layers in the neural network. We propose a quasi neural network to approximate the distribution propagation, which is a neural network with continuous parameters and smooth activation function. We derive the neural tangent kernel (NTK) for this quasi neural network, and show that the eigenvalue of NTK decays at approximately exponential rate, which is comparable to that of Gaussian kernel with randomized scale. This in turn indicates that the Reproducing Kernel Hilbert Space (RKHS) of a binary weight neural network covers a strict subset of functions compared with the one with real value weights. We use experiments to verify that the quasi neural network we proposed can well approximate binary weight neural network. Furthermore, binary weight neural network gives a lower generalization gap compared with real value weight neural network, which is similar to the difference between Gaussian kernel and Laplace kernel.