 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does SGD favor flat minima? A quantitative characterization via linear stability
Paper and Code
Jul 06, 2022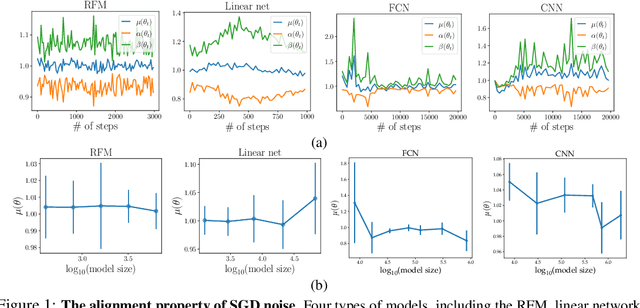
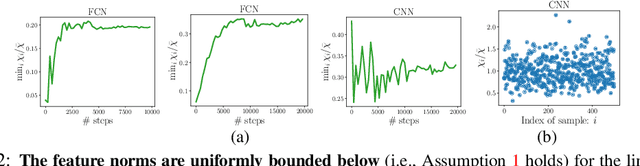

The observation that stochastic gradient descent (SGD) favors flat minima has played a fundamental role in understanding implicit regularization of SGD and guiding the tuning of hyperparameters. In this paper, we provide a quantitative explanation of this striking phenomenon by relating the particular noise structure of SGD to its \emph{linear stability} (Wu et al., 2018). Specifically, we consider training over-parameterized models with square loss. We prove that if a global minimum $\theta^*$ is linearly stable for SGD, then it must satisfy $\|H(\theta^*)\|_F\leq O(\sqrt{B}/\eta)$, where $\|H(\theta^*)\|_F, B,\eta$ denote the Frobenius norm of Hessian at $\theta^*$, batch size, and learning rate, respectively. Otherwise, SGD will escape from that minimum \emph{exponentially} fast. Hence, for minima accessible to SGD, the flatness -- as measured by the Frobenius norm of the Hessian -- is bounded independently of the model size and sample size. The key to obtaining these results is exploiting the particular geometry awareness of SGD noise: 1) the noise magnitude is proportional to loss value; 2) the noise directions concentrate in the sharp directions of local landscape. This property of SGD noise provably holds for linear networks and random feature models (RFMs) and is empirically verified for nonlinear networks. Moreover, the validity and practical relevance of our theoretical findings are justified by extensive numerical experiments.