 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen CNN Meet with ViT: Towards Semi-Supervised Learning for Multi-Class Medical Image Semantic Segmentation
Paper and Code

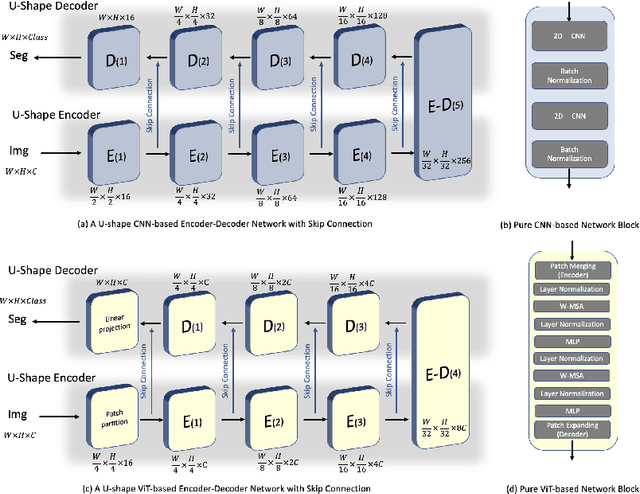
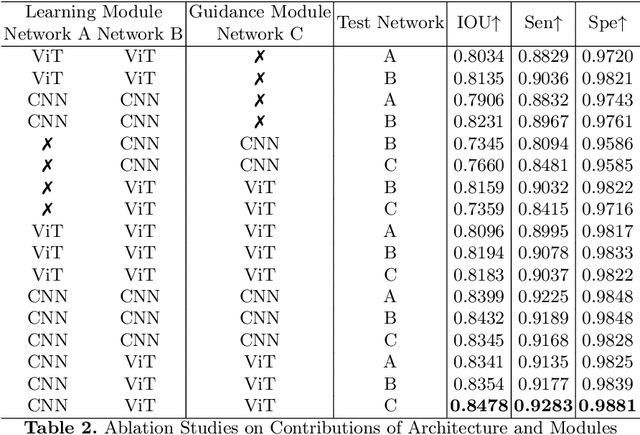
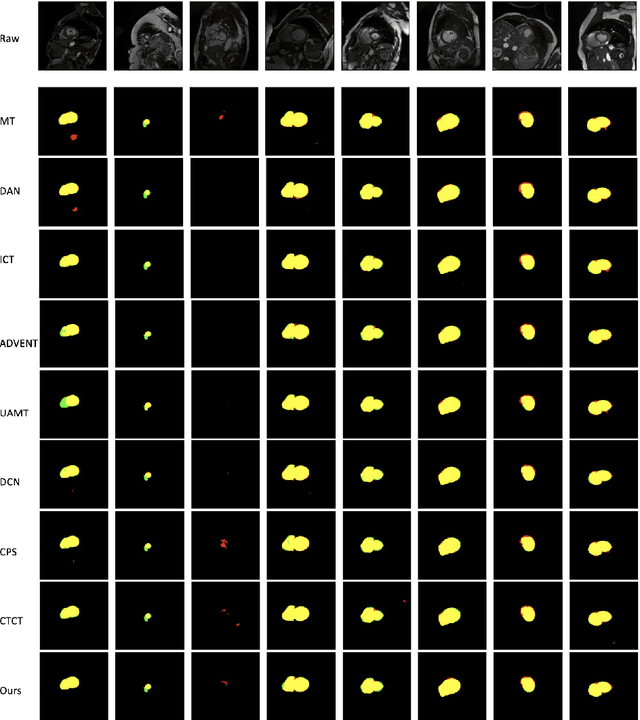
Due to the lack of quality annotation in medical imaging community, semi-supervised learning methods are highly valued in image semantic segmentation tasks. In this paper, an advanced consistency-aware pseudo-label-based self-ensembling approach is presented to fully utilize the power of Vision Transformer(ViT) and Convolutional Neural Network(CNN) in semi-supervised learning. Our proposed framework consists of a feature-learning module which is enhanced by ViT and CNN mutually, and a guidance module which is robust for consistency-aware purposes. The pseudo labels are inferred and utilized recurrently and separately by views of CNN and ViT in the feature-learning module to expand the data set and are beneficial to each other. Meanwhile, a perturbation scheme is designed for the feature-learning module, and averaging network weight is utilized to develop the guidance module. By doing so, the framework combines the feature-learning strength of CNN and ViT, strengthens the performance via dual-view co-training, and enables consistency-aware supervision in a semi-supervised manner. A topological exploration of all alternative supervision modes with CNN and ViT are detailed validated, demonstrating the most promising performance and specific setting of our method on semi-supervised medical image segmentation tasks. Experimental results show that the proposed method achieves state-of-the-art performance on a public benchmark data set with a variety of metrics. The code is publicly available.