 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and Why is Unsupervised Neural Machine Translation Useless?
Paper and Code
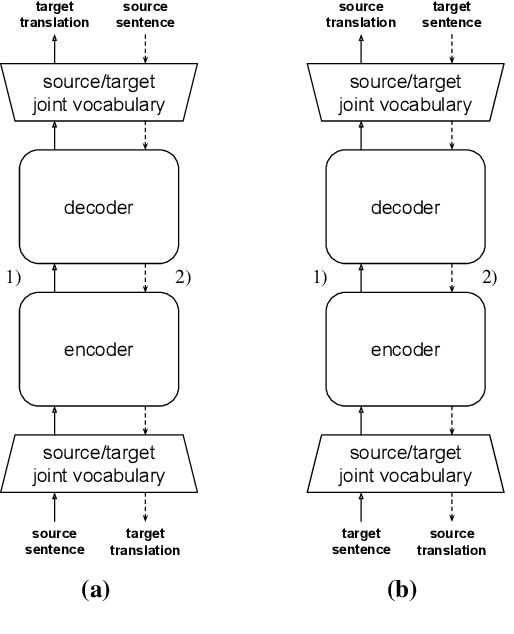
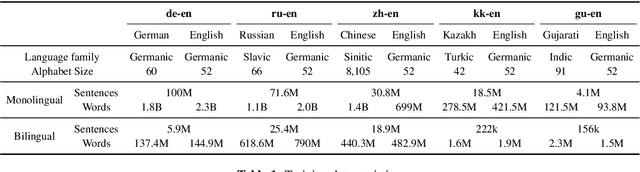
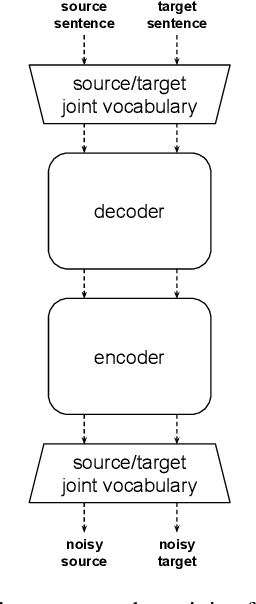
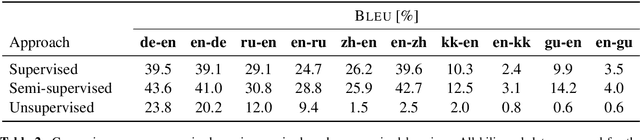
This paper studies the practicality of the current state-of-the-art unsupervised methods in neural machine translation (NMT). In ten translation tasks with various data settings, we analyze the conditions under which the unsupervised methods fail to produce reasonable translations. We show that their performance is severely affected by linguistic dissimilarity and domain mismatch between source and target monolingual data. Such conditions are common for low-resource language pairs, where unsupervised learning works poorly. In all of our experiments, supervised and semi-supervised baselines with 50k-sentence bilingual data outperform the best unsupervised results. Our analyses pinpoint the limits of the current unsupervised NMT and also suggest immediate research directions.