 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters to You? Towards Visual Representation Alignment for Robot Learning
Paper and Code
Oct 11, 2023

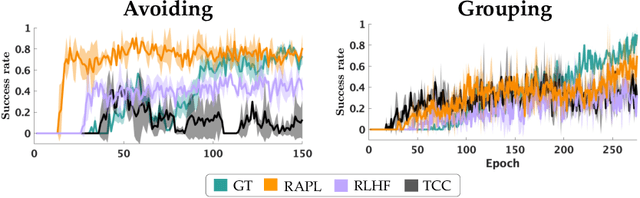

When operating in service of people, robots need to optimize rewards aligned with end-user preferences. Since robots will rely on raw perceptual inputs like RGB images, their rewards will inevitably use visual representations. Recently there has been excitement in using representations from pre-trained visual models, but key to making these work in robotics is fine-tuning, which is typically done via proxy tasks like dynamics prediction or enforcing temporal cycle-consistency. However, all these proxy tasks bypass the human's input on what matters to them, exacerbating spurious correlations and ultimately leading to robot behaviors that are misaligned with user preferences. In this work, we propose that robots should leverage human feedback to align their visual representations with the end-user and disentangle what matters for the task. We propose Representation-Aligned Preference-based Learning (RAPL), a method for solving the visual representation alignment problem and visual reward learning problem through the lens of preference-based learning and optimal transport. Across experiments in X-MAGICAL and in robotic manipulation, we find that RAPL's reward consistently generates preferred robot behaviors with high sample efficiency, and shows strong zero-shot generalization when the visual representation is learned from a different embodiment than the robot's.