 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is a meaningful representation of protein sequences?
Paper and Code
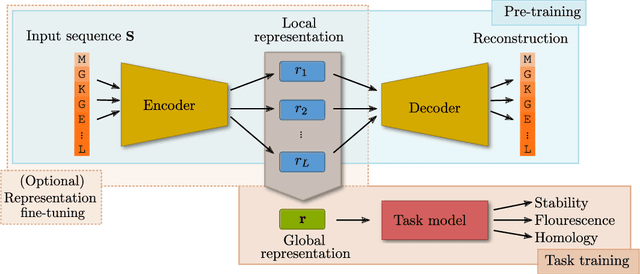
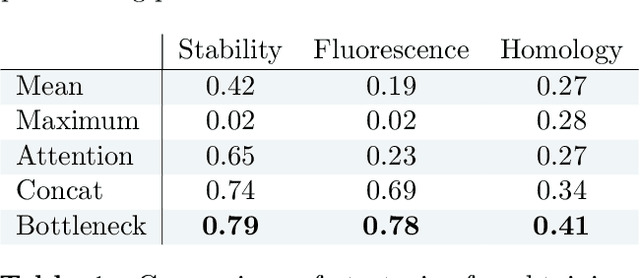
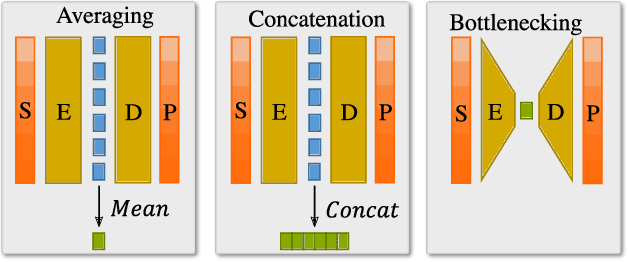
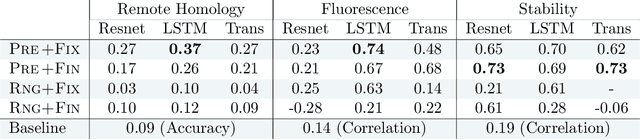
How we choose to represent our data has a fundamental impact on our ability to subsequently extract information from them. Machine learning promises to automatically determine efficient representations from large unstructured datasets, such as those arising in biology. However, empirical evidence suggests that seemingly minor changes to these machine learning models yield drastically different data representations that result in different biological interpretations of data. This begs the question of what even constitutes the most meaningful representation. Here, we approach this question for representations of protein sequences, which have received considerable attention in the recent literature. We explore two key contexts in which representations naturally arise: transfer learning and interpretable learning. In the first context, we demonstrate that several contemporary practices yield suboptimal performance, and in the latter we demonstrate that taking representation geometry into account significantly improves interpretability and lets the models reveal biological information that is otherwise obscured.