 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat If We Simply Swap the Two Text Fragments? A Straightforward yet Effective Way to Test the Robustness of Methods to Confounding Signals in Nature Language Inference Tasks
Paper and Code
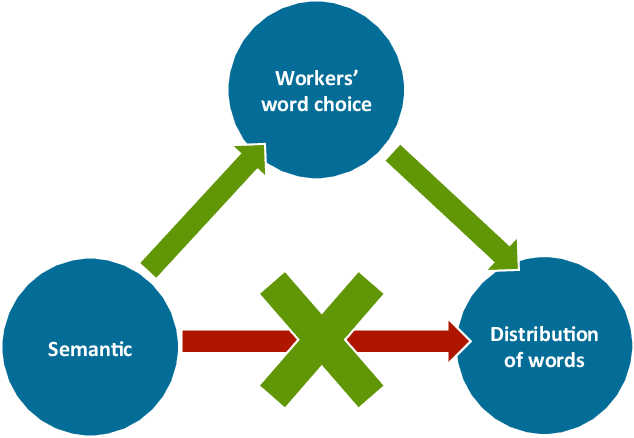
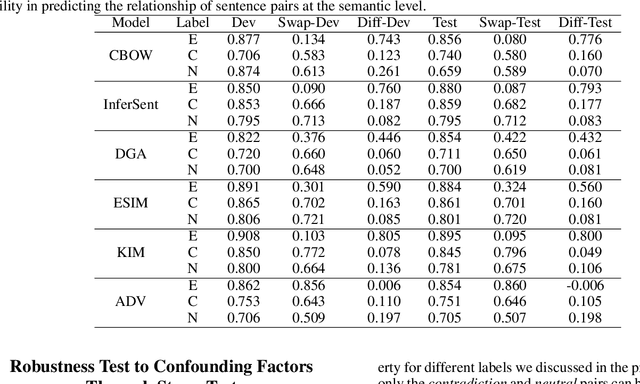
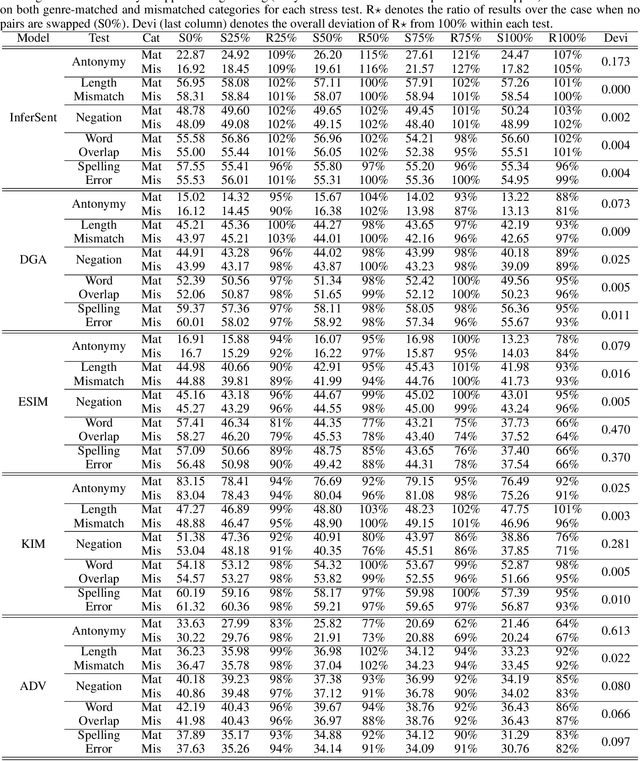

Nature language inference (NLI) task is a predictive task of determining the inference relationship of a pair of natural language sentences. With the increasing popularity of NLI, many state-of-the-art predictive models have been proposed with impressive performances. However, several works have noticed the statistical irregularities in the collected NLI data set that may result in an over-estimated performance of these models and proposed remedies. In this paper, we further investigate the statistical irregularities, what we refer as confounding factors, of the NLI data sets. With the belief that some NLI labels should preserve under swapping operations, we propose a simple yet effective way (swapping the two text fragments) of evaluating the NLI predictive models that naturally mitigate the observed problems. Further, we continue to train the predictive models with our swapping manner and propose to use the deviation of the model's evaluation performances under different percentages of training text fragments to be swapped to describe the robustness of a predictive model. Our evaluation metrics leads to some interesting understandings of recent published NLI methods. Finally, we also apply the swapping operation on NLI models to see the effectiveness of this straightforward method in mitigating the confounding factor problems in training generic sentence embeddings for other NLP transfer tasks.