 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do we need to build explainable AI systems for the medical domain?
Paper and Code
Dec 28, 2017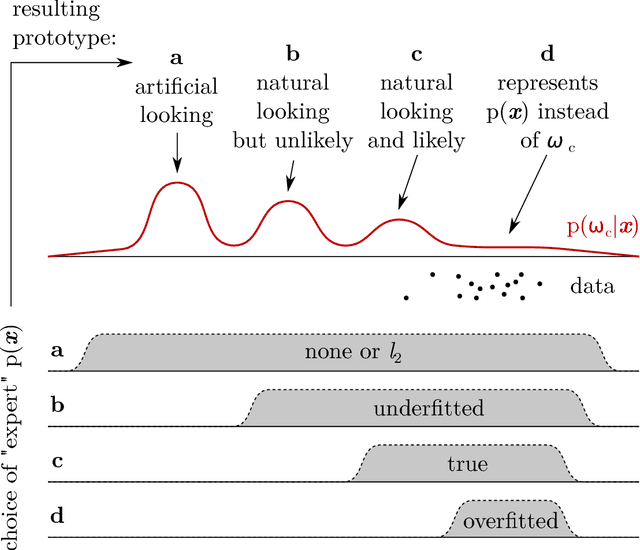

Artificial intelligence (AI) generally and machine learning (ML) specifically demonstrate impressive practical success in many different application domains, e.g. in autonomous driving, speech recognition, or recommender systems. Deep learning approaches, trained on extremely large data sets or using reinforcement learning methods have even exceeded human performance in visual tasks, particularly on playing games such as Atari, or mastering the game of Go. Even in the medical domain there are remarkable results. The central problem of such models is that they are regarded as black-box models and even if we understand the underlying mathematical principles, they lack an explicit declarative knowledge representation, hence have difficulty in generating the underlying explanatory structures. This calls for systems enabling to make decisions transparent, understandable and explainable. A huge motivation for our approach are rising legal and privacy aspects. The new European General Data Protection Regulation entering into force on May 25th 2018, will make black-box approaches difficult to use in business. This does not imply a ban on automatic learning approaches or an obligation to explain everything all the time, however, there must be a possibility to make the results re-traceable on demand. In this paper we outline some of our research topics in the context of the relatively new area of explainable-AI with a focus on the application in medicine, which is a very special domain. This is due to the fact that medical professionals are working mostly with distributed heterogeneous and complex sources of data. In this paper we concentrate on three sources: images, *omics data and text. We argue that research in explainable-AI would generally help to facilitate the implementation of AI/ML in the medical domain, and specifically help to facilitate transparency and trust.