 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-of-evidence 2.0 with shrinkage and spline-binning
Paper and Code

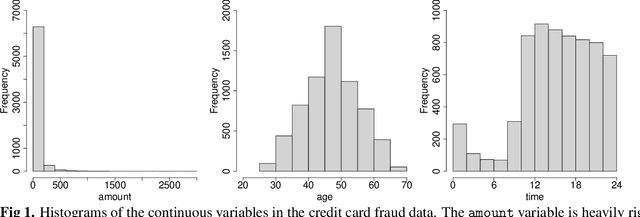
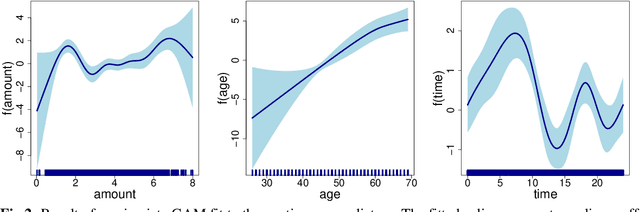
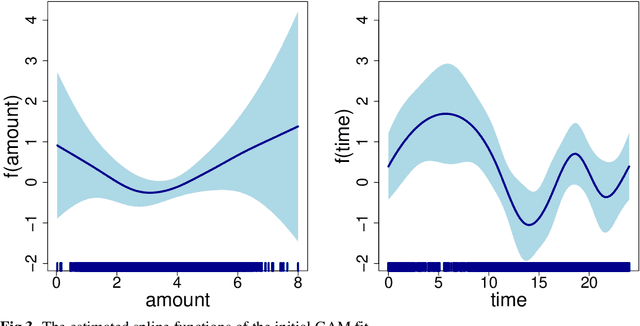
In many practical applications, such as fraud detection, credit risk modeling or medical decision making, classification models for assigning instances to a predefined set of classes are required to be both precise as well as interpretable. Linear modeling methods such as logistic regression are often adopted, since they offer an acceptable balance between precision and interpretability. Linear methods, however, are not well equipped to handle categorical predictors with high-cardinality or to exploit non-linear relations in the data. As a solution, data preprocessing methods such as weight-of-evidence are typically used for transforming the predictors. The binning procedure that underlies the weight-of-evidence approach, however, has been little researched and typically relies on ad-hoc or expert driven procedures. The objective in this paper, therefore, is to propose a formalized, data-driven and powerful method. To this end, we explore the discretization of continuous variables through the binning of spline functions, which allows for capturing non-linear effects in the predictor variables and yields highly interpretable predictors taking only a small number of discrete values. Moreover, we extend upon the weight-of-evidence approach and propose to estimate the proportions using shrinkage estimators. Together, this offers an improved ability to exploit both non-linear and categorical predictors for achieving increased classification precision, while maintaining interpretability of the resulting model and decreasing the risk of overfitting. We present the results of a series of experiments in a fraud detection setting, which illustrate the effectiveness of the presented approach. We facilitate reproduction of the presented results and adoption of the proposed approaches by providing both the dataset and the code for implementing the experiments and the presented approach.