 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised PLDA Training
Paper and Code
May 23, 2017
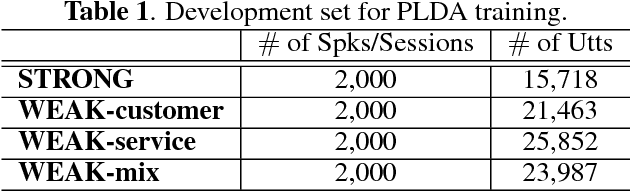

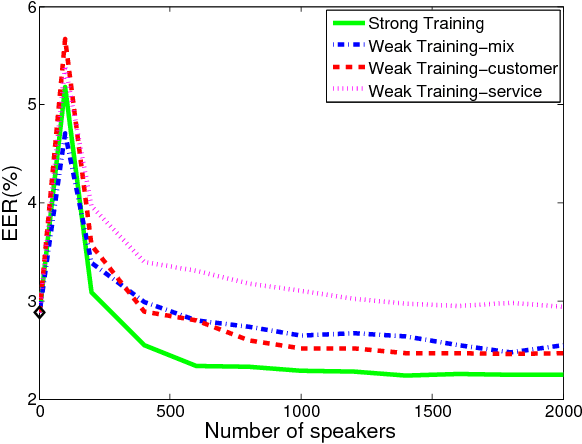
PLDA is a popular normalization approach for the i-vector model, and it has delivered state-of-the-art performance in speaker verification. However, PLDA training requires a large amount of labelled development data, which is highly expensive in most cases. We present a cheap PLDA training approach, which assumes that speakers in the same session can be easily separated, and speakers in different sessions are simply different. This results in `weak labels' which are not fully accurate but cheap, leading to a weak PLDA training. Our experimental results on real-life large-scale telephony customer service achieves demonstrated that the weak training can offer good performance when human-labelled data are limited. More interestingly, the weak training can be employed as a discriminative adaptation approach, which is more efficient than the prevailing unsupervised method when human-labelled data are insufficient.