 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Medical Diagnosis and Localization from Multiple Resolutions
Paper and Code
Mar 21, 2018
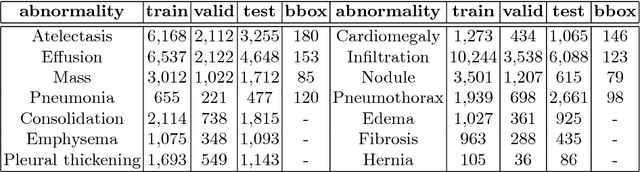
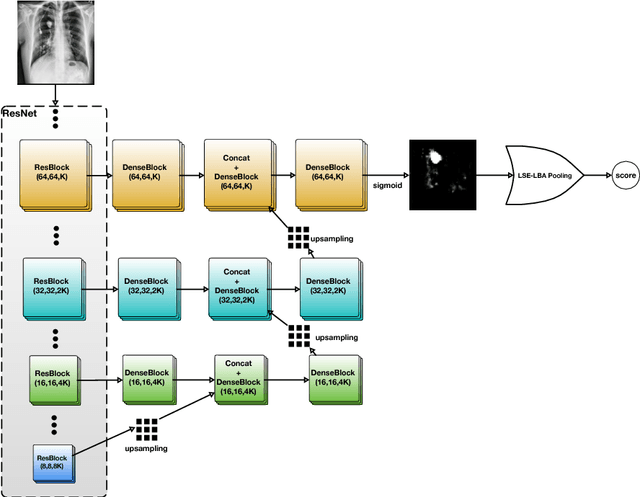
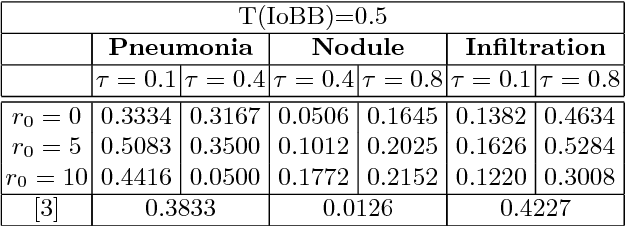
Diagnostic imaging often requires the simultaneous identification of a multitude of findings of varied size and appearance. Beyond global indication of said findings, the prediction and display of localization information improves trust in and understanding of results when augmenting clinical workflow. Medical training data rarely includes more than global image-level labels as segmentations are time-consuming and expensive to collect. We introduce an approach to managing these practical constraints by applying a novel architecture which learns at multiple resolutions while generating saliency maps with weak supervision. Further, we parameterize the Log-Sum-Exp pooling function with a learnable lower-bounded adaptation (LSE-LBA) to build in a sharpness prior and better handle localizing abnormalities of different sizes using only image-level labels. Applying this approach to interpreting chest x-rays, we set the state of the art on 9 abnormalities in the NIH's CXR14 dataset while generating saliency maps with the highest resolution to date.