Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Paper and Code
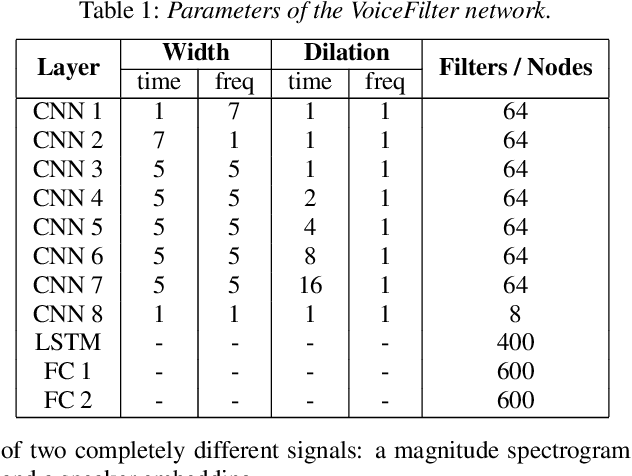
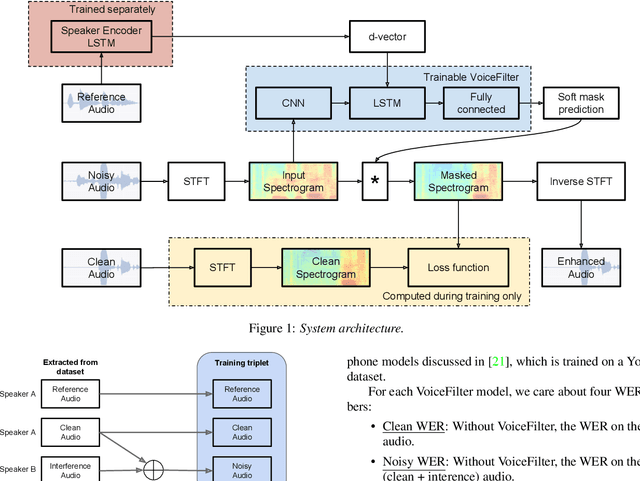
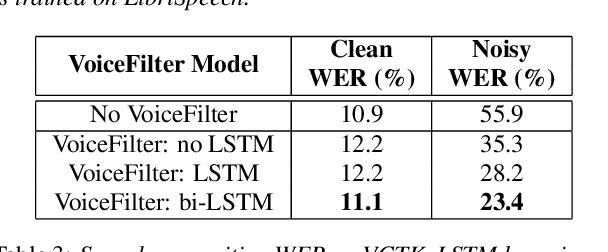
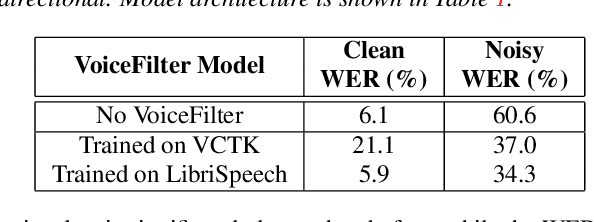
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
* To be submitted to ICASSP 2019
View paper on