Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViterbi Decoding of Directed Acyclic Transformer for Non-Autoregressive Machine Translation
Paper and Code



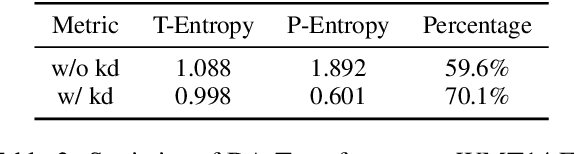
Non-autoregressive models achieve significant decoding speedup in neural machine translation but lack the ability to capture sequential dependency. Directed Acyclic Transformer (DA-Transformer) was recently proposed to model sequential dependency with a directed acyclic graph. Consequently, it has to apply a sequential decision process at inference time, which harms the global translation accuracy. In this paper, we present a Viterbi decoding framework for DA-Transformer, which guarantees to find the joint optimal solution for the translation and decoding path under any length constraint. Experimental results demonstrate that our approach consistently improves the performance of DA-Transformer while maintaining a similar decoding speedup.
* Findings of EMNLP 2022
View paper on