 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualNews : Benchmark and Challenges in Entity-aware Image Captioning
Paper and Code
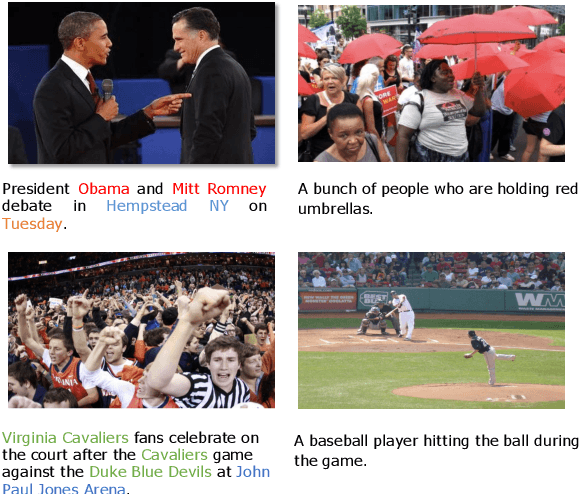
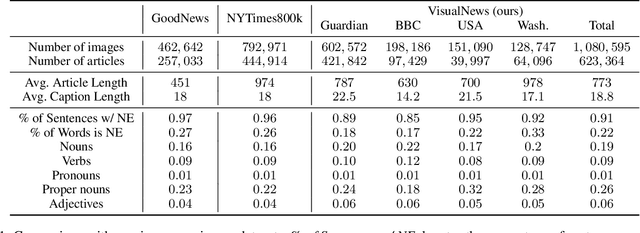
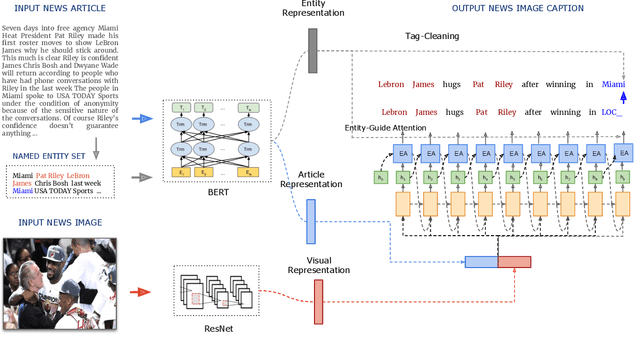
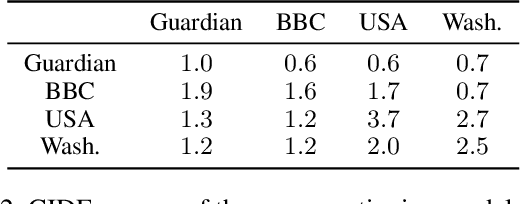
In this paper we propose VisualNews-Captioner, an entity-aware model for the task of news image captioning. We also introduce VisualNews, a large-scale benchmark consisting of more than one million news images along with associated news articles, image captions, author information, and other metadata. Unlike the standard image captioning task, news images depict situations where people, locations, and events are of paramount importance. Our proposed method is able to effectively combine visual and textual features to generate captions with richer information such as events and entities. More specifically, we propose an Entity-Aware module along with an Entity-Guide attention layer to encourage more accurate predictions for named entities. Our method achieves state-of-the-art results on both the GoodNews and VisualNews datasets while having significantly fewer parameters than competing methods. Our larger and more diverse VisualNews dataset further highlights the remaining challenges in captioning news images.