 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering based on Formal Logic
Paper and Code
Nov 08, 2021

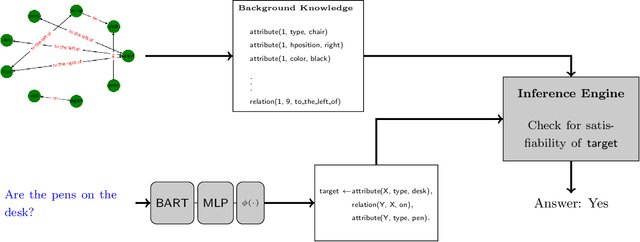
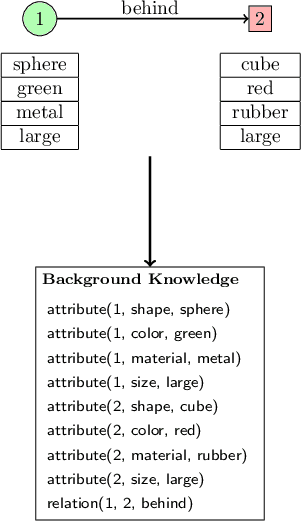
Visual question answering (VQA) has been gaining a lot of traction in the machine learning community in the recent years due to the challenges posed in understanding information coming from multiple modalities (i.e., images, language). In VQA, a series of questions are posed based on a set of images and the task at hand is to arrive at the answer. To achieve this, we take a symbolic reasoning based approach using the framework of formal logic. The image and the questions are converted into symbolic representations on which explicit reasoning is performed. We propose a formal logic framework where (i) images are converted to logical background facts with the help of scene graphs, (ii) the questions are translated to first-order predicate logic clauses using a transformer based deep learning model, and (iii) perform satisfiability checks, by using the background knowledge and the grounding of predicate clauses, to obtain the answer. Our proposed method is highly interpretable and each step in the pipeline can be easily analyzed by a human. We validate our approach on the CLEVR and the GQA dataset. We achieve near perfect accuracy of 99.6% on the CLEVR dataset comparable to the state of art models, showcasing that formal logic is a viable tool to tackle visual question answering. Our model is also data efficient, achieving 99.1% accuracy on CLEVR dataset when trained on just 10% of the training data.