 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Linguistic Agent: Towards Collaborative Contextual Object Reasoning
Paper and Code
Nov 15, 2024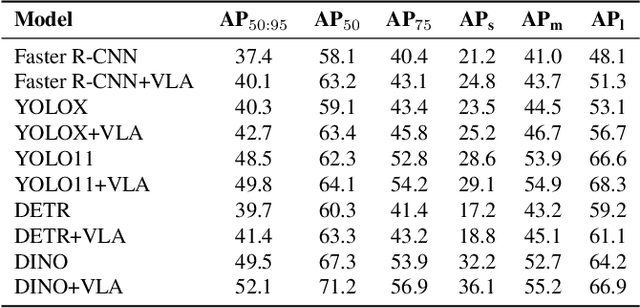

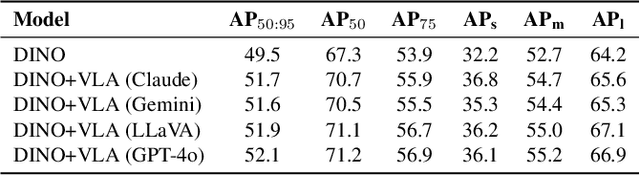
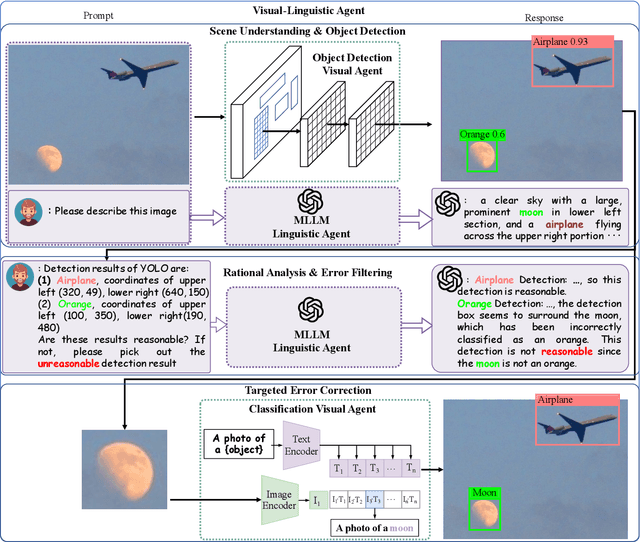
Multimodal Large Language Models (MLLMs) excel at descriptive tasks within images but often struggle with precise object localization, a critical element for reliable visual interpretation. In contrast, traditional object detection models provide high localization accuracy but frequently generate detections lacking contextual coherence due to limited modeling of inter-object relationships. To address this fundamental limitation, we introduce the \textbf{Visual-Linguistic Agent (VLA), a collaborative framework that combines the relational reasoning strengths of MLLMs with the precise localization capabilities of traditional object detectors. In the VLA paradigm, the MLLM serves as a central Linguistic Agent, working collaboratively with specialized Vision Agents for object detection and classification. The Linguistic Agent evaluates and refines detections by reasoning over spatial and contextual relationships among objects, while the classification Vision Agent offers corrective feedback to improve classification accuracy. This collaborative approach enables VLA to significantly enhance both spatial reasoning and object localization, addressing key challenges in multimodal understanding. Extensive evaluations on the COCO dataset demonstrate substantial performance improvements across multiple detection models, highlighting VLA's potential to set a new benchmark in accurate and contextually coherent object detection.