 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Backtracking Teleoperation: A Data Collection Protocol for Offline Image-Based Reinforcement Learning
Paper and Code
Oct 05, 2022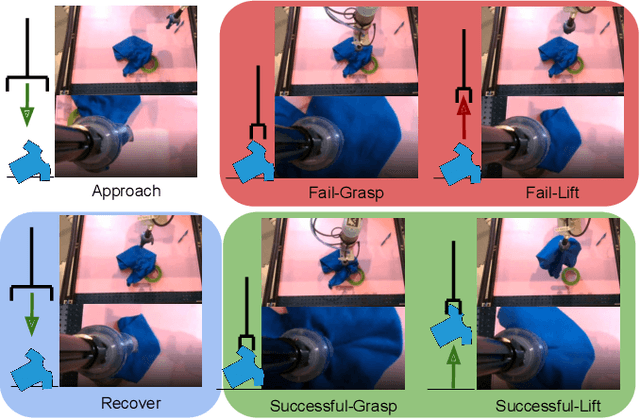
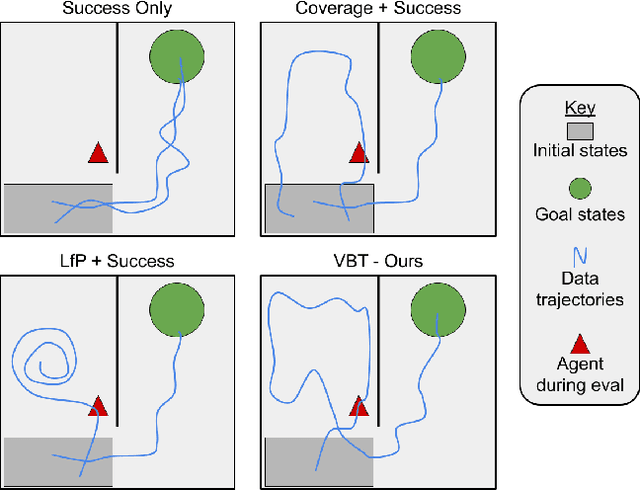
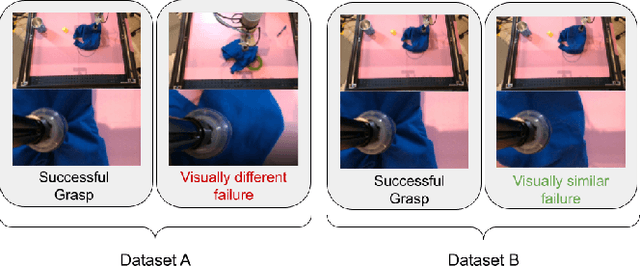
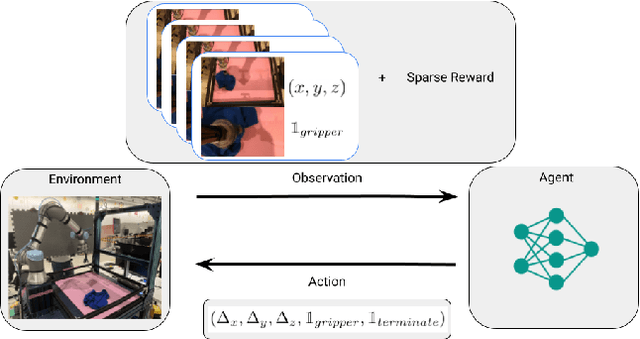
We consider how to most efficiently leverage teleoperator time to collect data for learning robust image-based value functions and policies for sparse reward robotic tasks. To accomplish this goal, we modify the process of data collection to include more than just successful demonstrations of the desired task. Instead we develop a novel protocol that we call Visual Backtracking Teleoperation (VBT), which deliberately collects a dataset of visually similar failures, recoveries, and successes. VBT data collection is particularly useful for efficiently learning accurate value functions from small datasets of image-based observations. We demonstrate VBT on a real robot to perform continuous control from image observations for the deformable manipulation task of T-shirt grasping. We find that by adjusting the data collection process we improve the quality of both the learned value functions and policies over a variety of baseline methods for data collection. Specifically, we find that offline reinforcement learning on VBT data outperforms standard behavior cloning on successful demonstration data by 13% when both methods are given equal-sized datasets of 60 minutes of data from the real robot.