 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-and-Language Pretrained Models: A Survey
Paper and Code
Apr 28, 2022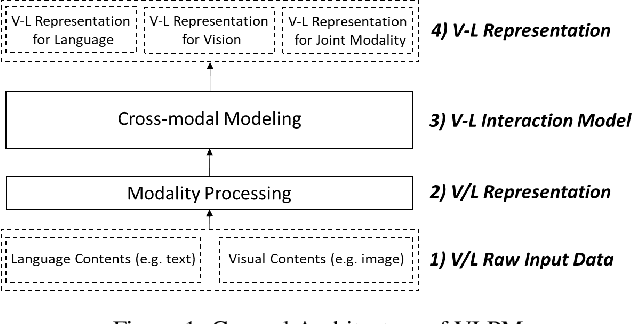
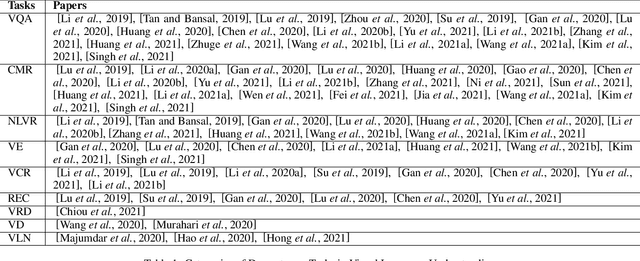
Pretrained models have produced great success in both Computer Vision (CV) and Natural Language Processing (NLP). This progress leads to learning joint representations of vision and language pretraining by feeding visual and linguistic contents into a multi-layer transformer, Visual-Language Pretrained Models (VLPMs). In this paper, we present an overview of the major advances achieved in VLPMs for producing joint representations of vision and language. As the preliminaries, we briefly describe the general task definition and genetic architecture of VLPMs. We first discuss the language and vision data encoding methods and then present the mainstream VLPM structure as the core content. We further summarise several essential pretraining and fine-tuning strategies. Finally, we highlight three future directions for both CV and NLP researchers to provide insightful guidance.