 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Cross-modal Auxiliary Network for Multimodal Sentiment Analysis
Paper and Code
Aug 30, 2022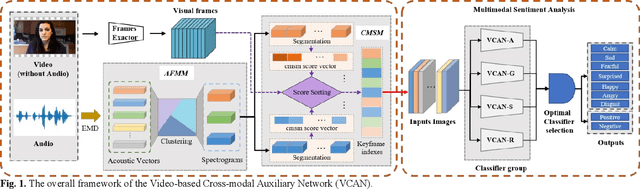



Multimodal sentiment analysis has a wide range of applications due to its information complementarity in multimodal interactions. Previous works focus more on investigating efficient joint representations, but they rarely consider the insufficient unimodal features extraction and data redundancy of multimodal fusion. In this paper, a Video-based Cross-modal Auxiliary Network (VCAN) is proposed, which is comprised of an audio features map module and a cross-modal selection module. The first module is designed to substantially increase feature diversity in audio feature extraction, aiming to improve classification accuracy by providing more comprehensive acoustic representations. To empower the model to handle redundant visual features, the second module is addressed to efficiently filter the redundant visual frames during integrating audiovisual data. Moreover, a classifier group consisting of several image classification networks is introduced to predict sentiment polarities and emotion categories. Extensive experimental results on RAVDESS, CMU-MOSI, and CMU-MOSEI benchmarks indicate that VCAN is significantly superior to the state-of-the-art methods for improving the classification accuracy of multimodal sentiment analysis.