 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGStore: A Multimodal Extension to SPARQL for Querying RDF Scene Graph
Paper and Code


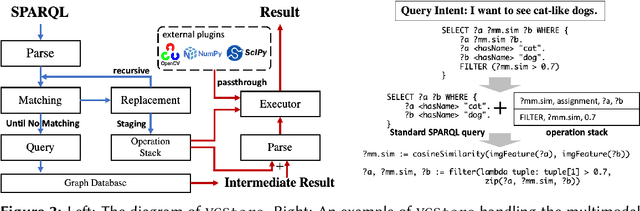

Semantic Web technology has successfully facilitated many RDF models with rich data representation methods. It also has the potential ability to represent and store multimodal knowledge bases such as multimodal scene graphs. However, most existing query languages, especially SPARQL, barely explore the implicit multimodal relationships like semantic similarity, spatial relations, etc. We first explored this issue by organizing a large-scale scene graph dataset, namely Visual Genome, in the RDF graph database. Based on the proposed RDF-stored multimodal scene graph, we extended SPARQL queries to answer questions containing relational reasoning about color, spatial, etc. Further demo (i.e., VGStore) shows the effectiveness of customized queries and displaying multimodal data.