 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGFace2: A dataset for recognising faces across pose and age
Paper and Code
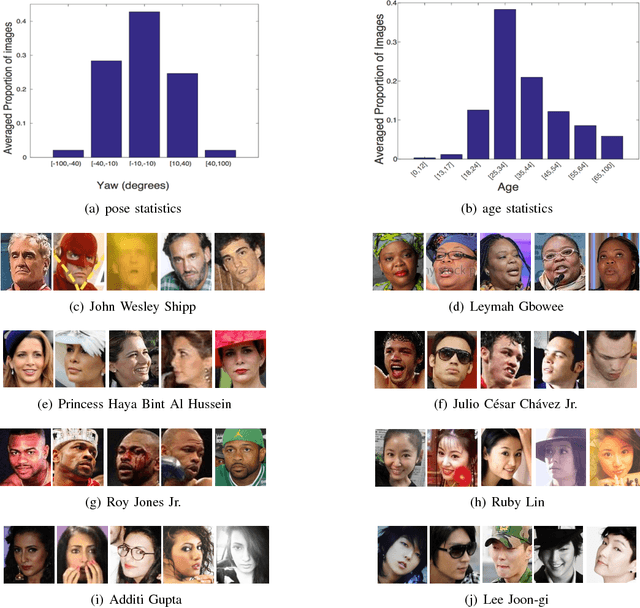
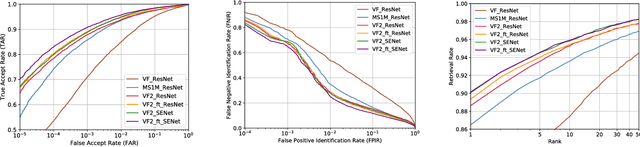
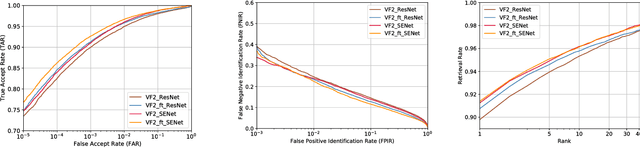

In this paper, we introduce a new large-scale face dataset named VGGFace2. The dataset contains 3.31 million images of 9131 subjects, with an average of 362.6 images for each subject. Images are downloaded from Google Image Search and have large variations in pose, age, illumination, ethnicity and profession (e.g. actors, athletes, politicians). The dataset was collected with three goals in mind: (i) to have both a large number of identities and also a large number of images for each identity; (ii) to cover a large range of pose, age and ethnicity; and (iii) to minimize the label noise. We describe how the dataset was collected, in particular the automated and manual filtering stages to ensure a high accuracy for the images of each identity. To assess face recognition performance using the new dataset, we train ResNet-50 (with and without Squeeze-and-Excitation blocks) Convolutional Neural Networks on VGGFace2, on MS- Celeb-1M, and on their union, and show that training on VGGFace2 leads to improved recognition performance over pose and age. Finally, using the models trained on these datasets, we demonstrate state-of-the-art performance on all the IARPA Janus face recognition benchmarks, e.g. IJB-A, IJB-B and IJB-C, exceeding the previous state-of-the-art by a large margin. Datasets and models are publicly available.