 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVectorization of hypotheses and speech for faster beam search in encoder decoder-based speech recognition
Paper and Code
Nov 12, 2018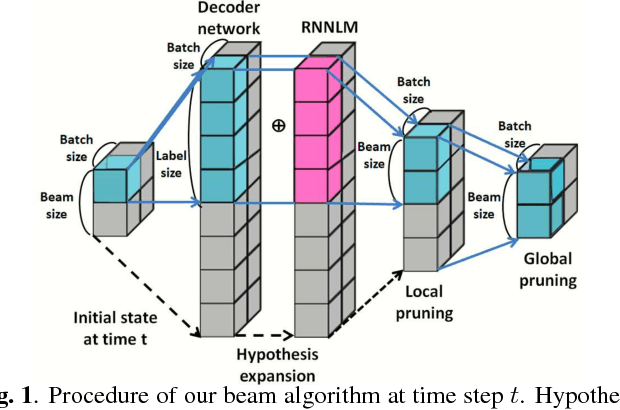
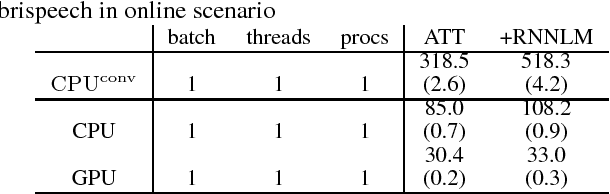
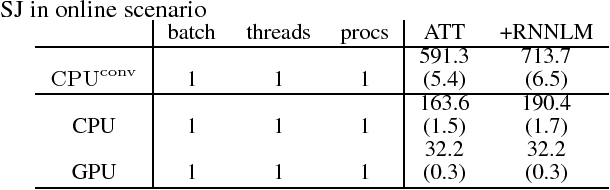
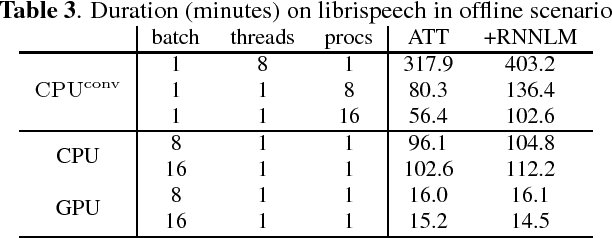
Attention-based encoder decoder network uses a left-to-right beam search algorithm in the inference step. The current beam search expands hypotheses and traverses the expanded hypotheses at the next time step. This traversal is implemented using a for-loop program in general, and it leads to speed down of the recognition process. In this paper, we propose a parallelism technique for beam search, which accelerates the search process by vectorizing multiple hypotheses to eliminate the for-loop program. We also propose a technique to batch multiple speech utterances for off-line recognition use, which reduces the for-loop program with regard to the traverse of multiple utterances. This extension is not trivial during beam search unlike during training due to several pruning and thresholding techniques for efficient decoding. In addition, our method can combine scores of external modules, RNNLM and CTC, in a batch as shallow fusion. We achieved 3.7 x speedup compared with the original beam search algorithm by vectoring hypotheses, and achieved 10.5 x speedup by further changing processing unit to GPU.