 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAuLT: Augmenting the Vision-and-Language Transformer with the Propagation of Deep Language Representations
Paper and Code
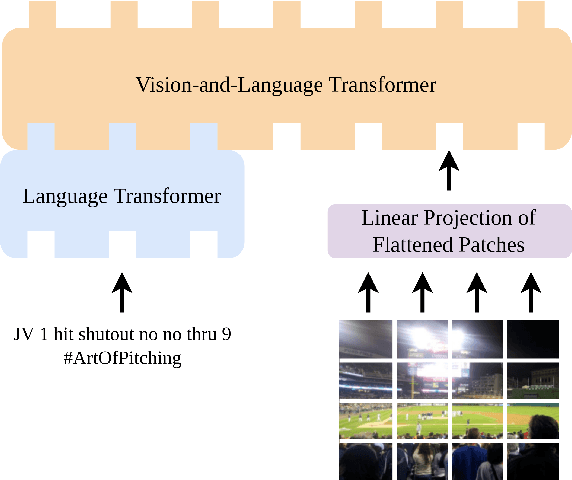

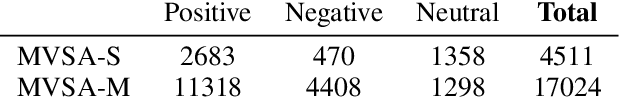

We propose the Vision-and-Augmented-Language Transformer (VAuLT). VAuLT is an extension of the popular Vision-and-Language Transformer (ViLT), and improves performance on vision-and-language tasks that involve more complex text inputs than image captions while having minimal impact on training and inference efficiency. ViLT, importantly, enables efficient training and inference in vision-and-language tasks, achieved by using a shallow image encoder. However, it is pretrained on captioning and similar datasets, where the language input is simple, literal, and descriptive, therefore lacking linguistic diversity. So, when working with multimedia data in the wild, such as multimodal social media data (in our work, Twitter), there is a notable shift from captioning language data, as well as diversity of tasks, and we indeed find evidence that the language capacity of ViLT is lacking instead. The key insight of VAuLT is to propagate the output representations of a large language model like BERT to the language input of ViLT. We show that such a strategy significantly improves over ViLT on vision-and-language tasks involving richer language inputs and affective constructs, such as TWITTER-2015, TWITTER-2017, MVSA-Single and MVSA-Multiple, but lags behind pure reasoning tasks such as the Bloomberg Twitter Text-Image Relationship dataset. We have released the code for all our experiments at https://github.com/gchochla/VAuLT.