 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational inference via Wasserstein gradient flows
Paper and Code
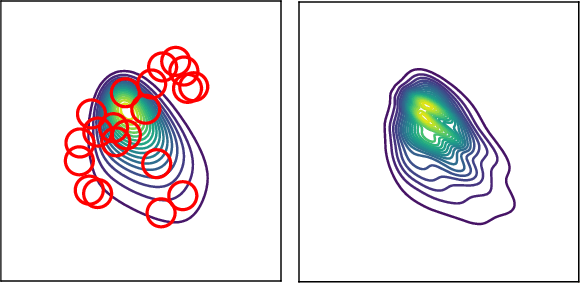
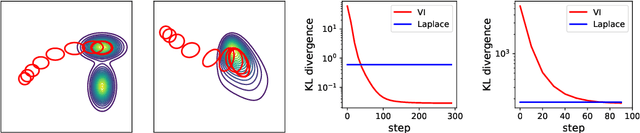
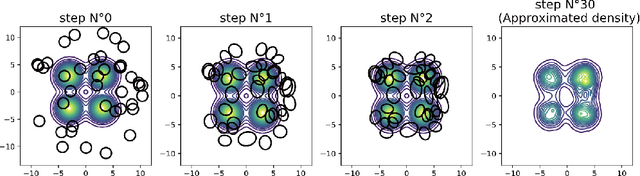
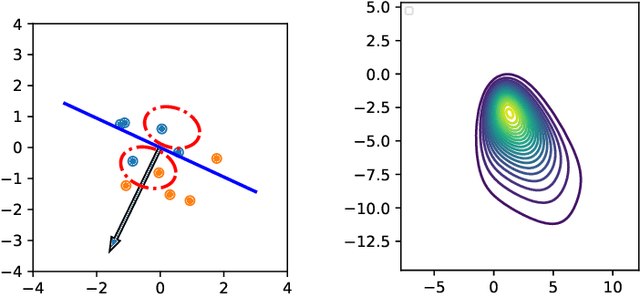
Along with Markov chain Monte Carlo (MCMC) methods, variational inference (VI) has emerged as a central computational approach to large-scale Bayesian inference. Rather than sampling from the true posterior $\pi$, VI aims at producing a simple but effective approximation $\hat \pi$ to $\pi$ for which summary statistics are easy to compute. However, unlike the well-studied MCMC methodology, VI is still poorly understood and dominated by heuristics. In this work, we propose principled methods for VI, in which $\hat \pi$ is taken to be a Gaussian or a mixture of Gaussians, which rest upon the theory of gradient flows on the Bures-Wasserstein space of Gaussian measures. Akin to MCMC, it comes with strong theoretical guarantees when $\pi$ is log-concave.