 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Bottleneck Adapters to Identify Cancer in Clinical Notes under Low-Resource Constraints
Paper and Code
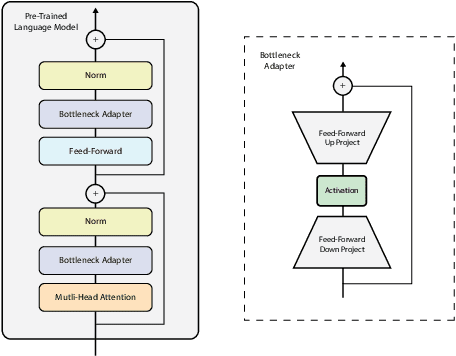
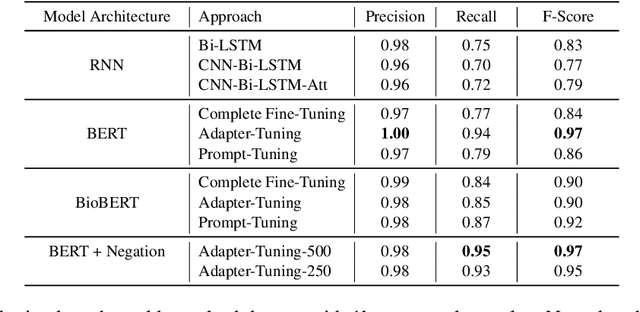
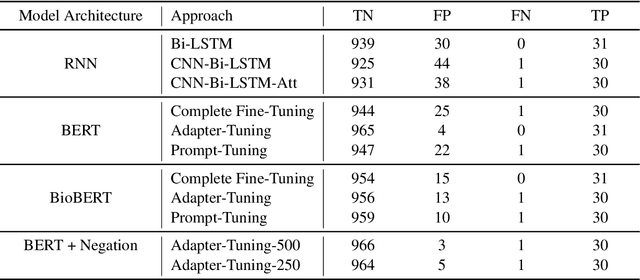
Processing information locked within clinical health records is a challenging task that remains an active area of research in biomedical NLP. In this work, we evaluate a broad set of machine learning techniques ranging from simple RNNs to specialised transformers such as BioBERT on a dataset containing clinical notes along with a set of annotations indicating whether a sample is cancer-related or not. Furthermore, we specifically employ efficient fine-tuning methods from NLP, namely, bottleneck adapters and prompt tuning, to adapt the models to our specialised task. Our evaluations suggest that fine-tuning a frozen BERT model pre-trained on natural language and with bottleneck adapters outperforms all other strategies, including full fine-tuning of the specialised BioBERT model. Based on our findings, we suggest that using bottleneck adapters in low-resource situations with limited access to labelled data or processing capacity could be a viable strategy in biomedical text mining. The code used in the experiments are going to be made available at https://github.com/omidrohanian/bottleneck-adapters.