 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUses and Abuses of the Cross-Entropy Loss: Case Studies in Modern Deep Learning
Paper and Code
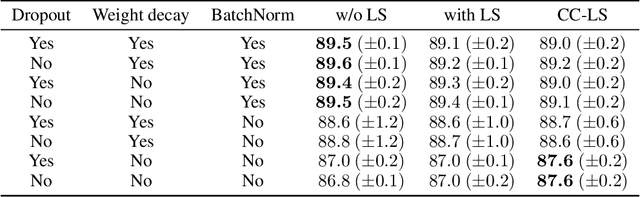
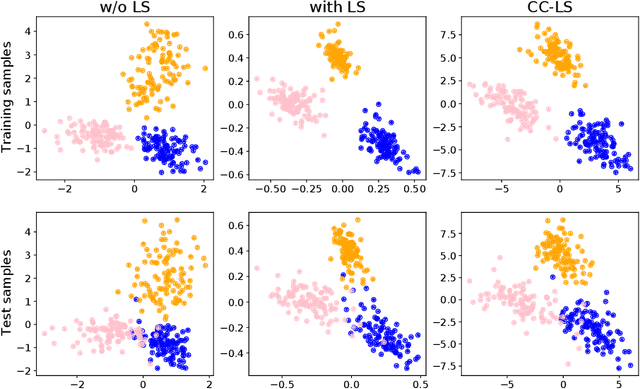

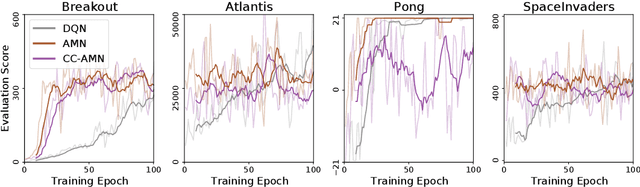
Modern deep learning is primarily an experimental science, in which empirical advances occasionally come at the expense of probabilistic rigor. Here we focus on one such example; namely the use of the categorical cross-entropy loss to model data that is not strictly categorical, but rather takes values on the simplex. This practice is standard in neural network architectures with label smoothing and actor-mimic reinforcement learning, amongst others. Drawing on the recently discovered continuous-categorical distribution, we propose probabilistically-inspired alternatives to these models, providing an approach that is more principled and theoretically appealing. Through careful experimentation, including an ablation study, we identify the potential for outperformance in these models, thereby highlighting the importance of a proper probabilistic treatment, as well as illustrating some of the failure modes thereof.