 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSER: Unified Semantic Enhancement with Momentum Contrast for Image-Text Retrieval
Paper and Code
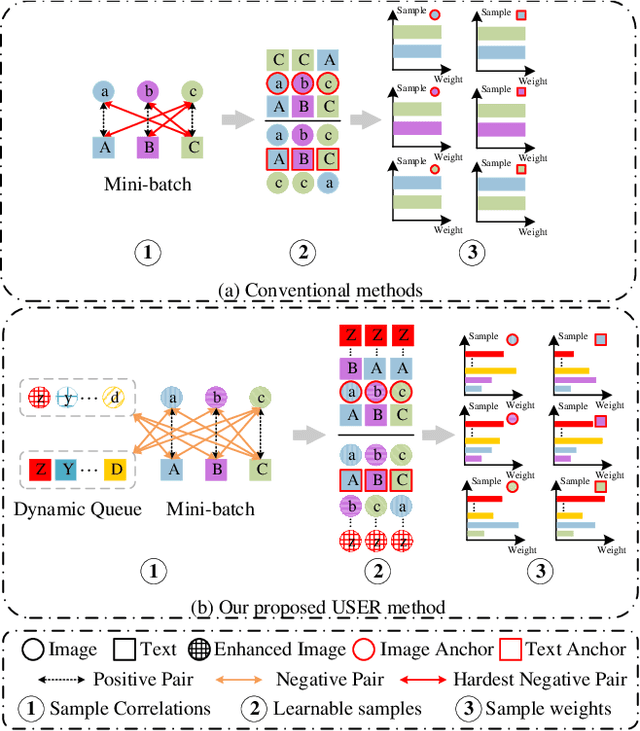
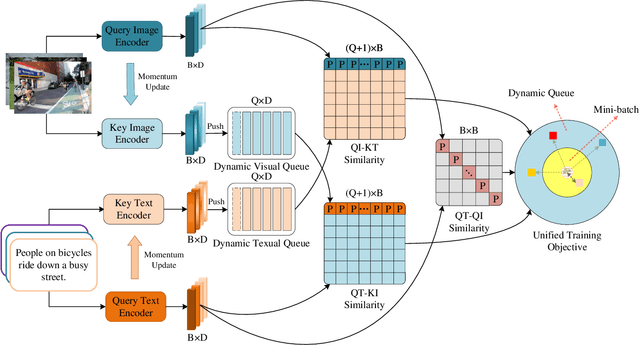
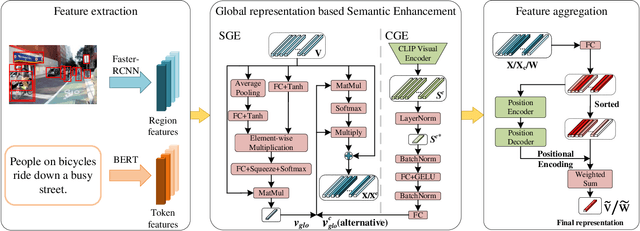
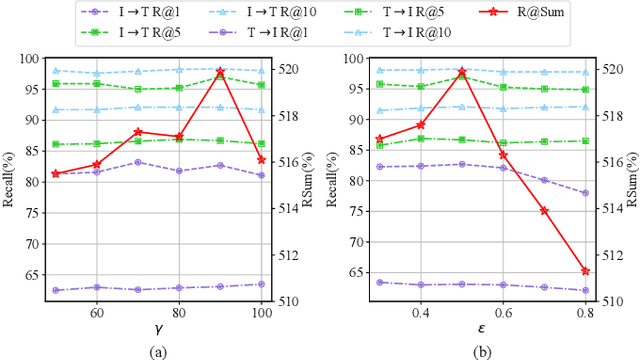
As a fundamental and challenging task in bridging language and vision domains, Image-Text Retrieval (ITR) aims at searching for the target instances that are semantically relevant to the given query from the other modality, and its key challenge is to measure the semantic similarity across different modalities. Although significant progress has been achieved, existing approaches typically suffer from two major limitations: (1) It hurts the accuracy of the representation by directly exploiting the bottom-up attention based region-level features where each region is equally treated. (2) It limits the scale of negative sample pairs by employing the mini-batch based end-to-end training mechanism. To address these limitations, we propose a Unified Semantic Enhancement Momentum Contrastive Learning (USER) method for ITR. Specifically, we delicately design two simple but effective Global representation based Semantic Enhancement (GSE) modules. One learns the global representation via the self-attention algorithm, noted as Self-Guided Enhancement (SGE) module. The other module benefits from the pre-trained CLIP module, which provides a novel scheme to exploit and transfer the knowledge from an off-the-shelf model, noted as CLIP-Guided Enhancement (CGE) module. Moreover, we incorporate the training mechanism of MoCo into ITR, in which two dynamic queues are employed to enrich and enlarge the scale of negative sample pairs. Meanwhile, a Unified Training Objective (UTO) is developed to learn from mini-batch based and dynamic queue based samples. Extensive experiments on the benchmark MSCOCO and Flickr30K datasets demonstrate the superiority of both retrieval accuracy and inference efficiency. Our source code will be released at https://github.com/zhangy0822/USER.