 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPV at CheckThat! 2021: Mitigating Cultural Differences for Identifying Multilingual Check-worthy Claims
Paper and Code
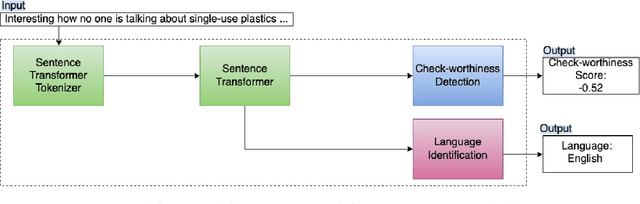
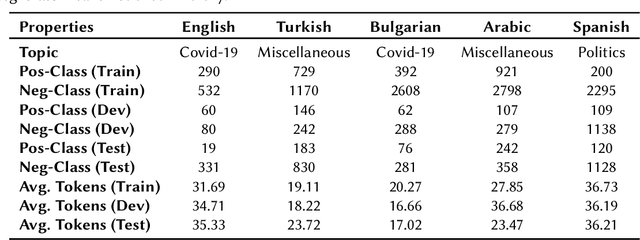
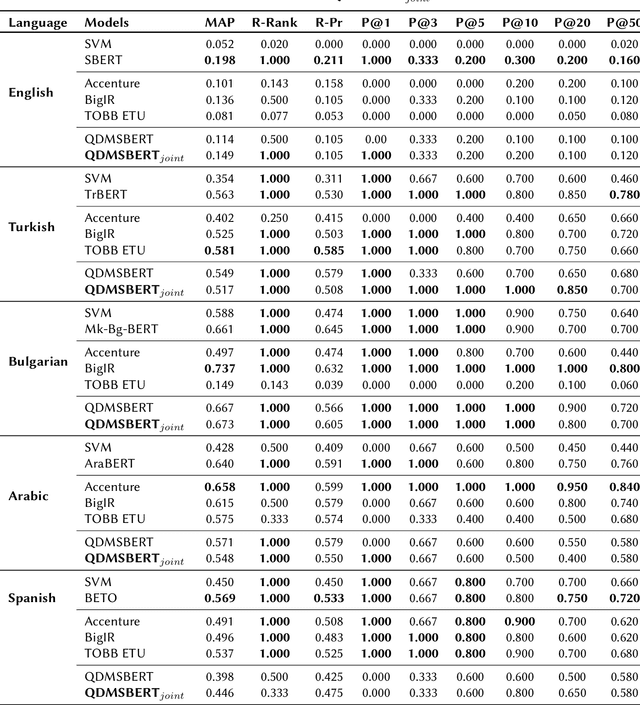
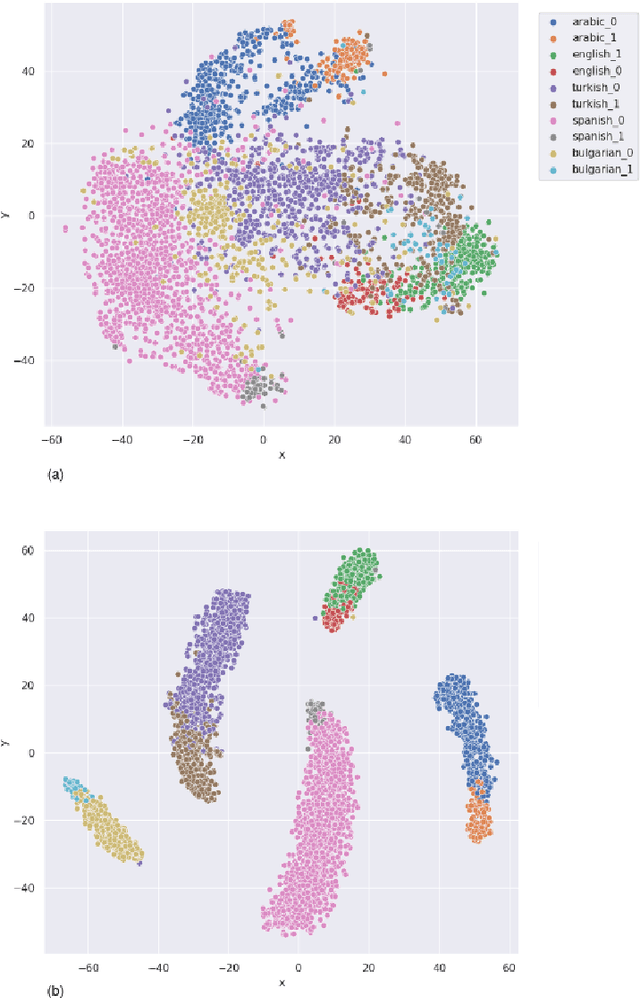
Identifying check-worthy claims is often the first step of automated fact-checking systems. Tackling this task in a multilingual setting has been understudied. Encoding inputs with multilingual text representations could be one approach to solve the multilingual check-worthiness detection. However, this approach could suffer if cultural bias exists within the communities on determining what is check-worthy.In this paper, we propose a language identification task as an auxiliary task to mitigate unintended bias.With this purpose, we experiment joint training by using the datasets from CLEF-2021 CheckThat!, that contain tweets in English, Arabic, Bulgarian, Spanish and Turkish. Our results show that joint training of language identification and check-worthy claim detection tasks can provide performance gains for some of the selected languages.