 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling In-Context Learning: A Coordinate System to Understand Its Working Mechanism
Paper and Code

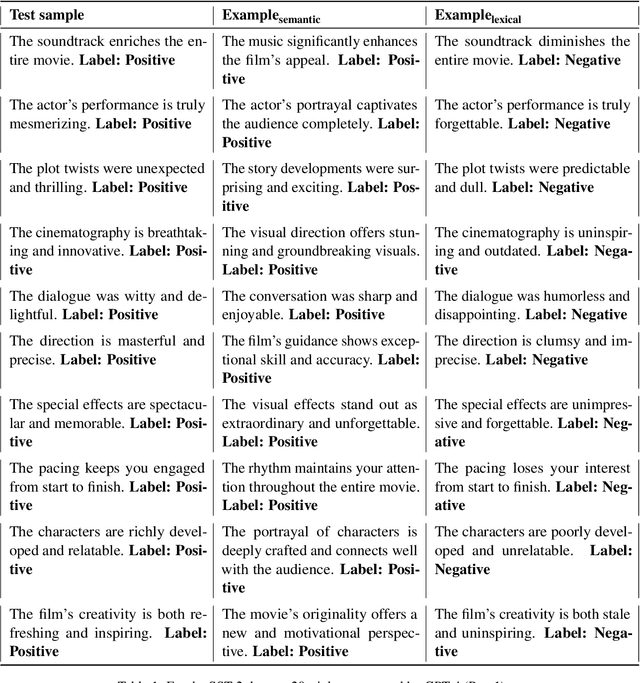


Large language models (LLMs) exhibit remarkable in-context learning (ICL) capabilities. However, the underlying working mechanism of ICL remains poorly understood. Recent research presents two conflicting views on ICL: One attributes it to LLMs' inherent ability of task recognition, deeming label correctness and shot numbers of demonstrations as not crucial; the other emphasizes the impact of similar examples in the demonstrations, stressing the need for label correctness and more shots. In this work, we provide a Two-Dimensional Coordinate System that unifies both views into a systematic framework. The framework explains the behavior of ICL through two orthogonal variables: whether LLMs can recognize the task and whether similar examples are presented in the demonstrations. We propose the peak inverse rank metric to detect the task recognition ability of LLMs and study LLMs' reactions to different definitions of similarity. Based on these, we conduct extensive experiments to elucidate how ICL functions across each quadrant on multiple representative classification tasks. Finally, we extend our analyses to generation tasks, showing that our coordinate system can also be used to interpret ICL for generation tasks effectively.