 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Pre-training with Structured Knowledge for Improving Natural Language Inference
Paper and Code
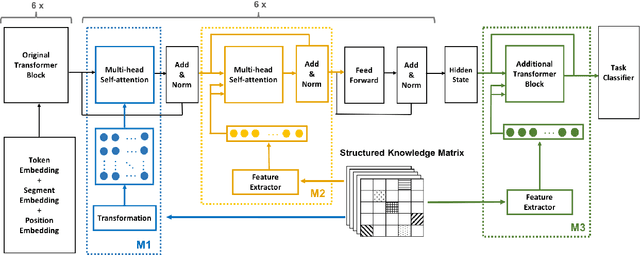
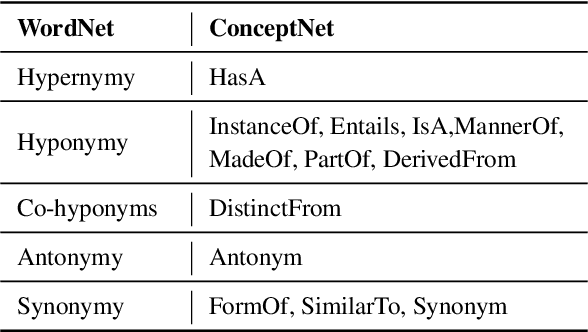
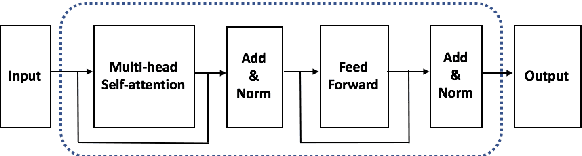
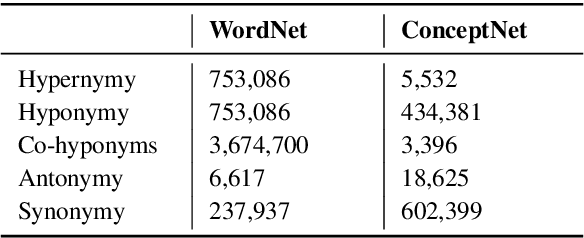
While recent research on natural language inference has considerably benefited from large annotated datasets, the amount of inference-related knowledge (including commonsense) provided in the annotated data is still rather limited. There have been two lines of approaches that can be used to further address the limitation: (1) unsupervised pretraining can leverage knowledge in much larger unstructured text data; (2) structured (often human-curated) knowledge has started to be considered in neural-network-based models for NLI. An immediate question is whether these two approaches complement each other, or how to develop models that can bring together their advantages. In this paper, we propose models that leverage structured knowledge in different components of pre-trained models. Our results show that the proposed models perform better than previous BERT-based state-of-the-art models. Although our models are proposed for NLI, they can be easily extended to other sentence or sentence-pair classification problems.