 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised pre-traing for sequence to sequence speech recognition
Paper and Code
Oct 28, 2019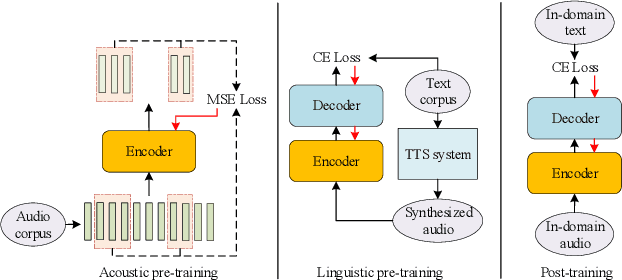

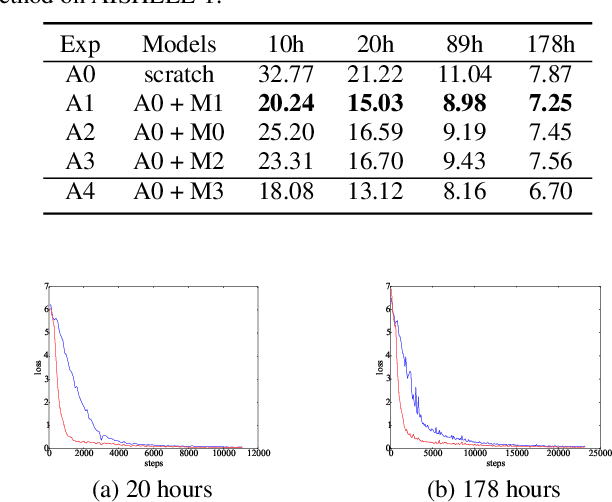
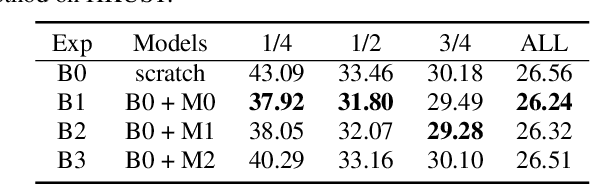
This paper proposes a novel approach to pre-train encoder-decoder sequence-to-sequence (seq2seq) model with unpaired speech and transcripts respectively. Our pre-training method is divided into two stages, named acoustic pre-trianing and linguistic pre-training. In the acoustic pre-training stage, we use a large amount of speech to pre-train the encoder by predicting masked speech feature chunks with its context. In the linguistic pre-training stage, we generate synthesized speech from a large number of transcripts using a single-speaker text to speech (TTS) system, and use the synthesized paired data to pre-train decoder. This two-stage pre-training method integrates rich acoustic and linguistic knowledge into seq2seq model, which will benefit downstream automatic speech recognition (ASR) tasks. The unsupervised pre-training is finished on AISHELL-2 dataset and we apply the pre-trained model to multiple paired data ratios of AISHELL-1 and HKUST. We obtain relative character error rate reduction (CERR) from 38.24% to 7.88% on AISHELL-1 and from 12.00% to 1.20% on HKUST. Besides, we apply our pretrained model to a cross-lingual case with CALLHOME dataset. For all six languages in CALLHOME dataset, our pre-training method makes model outperform baseline consistently.