 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Natural Language Inference via Decoupled Multimodal Contrastive Learning
Paper and Code
Oct 16, 2020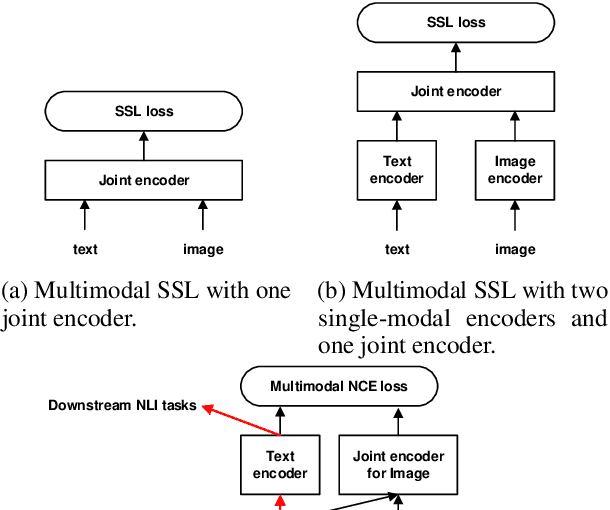
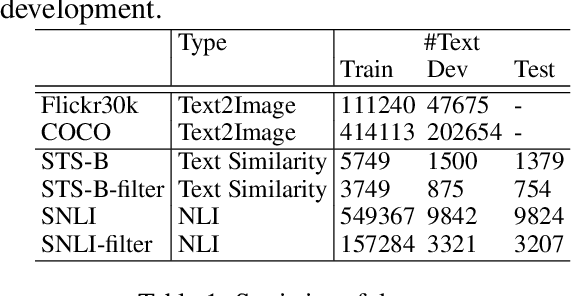
We propose to solve the natural language inference problem without any supervision from the inference labels via task-agnostic multimodal pretraining. Although recent studies of multimodal self-supervised learning also represent the linguistic and visual context, their encoders for different modalities are coupled. Thus they cannot incorporate visual information when encoding plain text alone. In this paper, we propose Multimodal Aligned Contrastive Decoupled learning (MACD) network. MACD forces the decoupled text encoder to represent the visual information via contrastive learning. Therefore, it embeds visual knowledge even for plain text inference. We conducted comprehensive experiments over plain text inference datasets (i.e. SNLI and STS-B). The unsupervised MACD even outperforms the fully-supervised BiLSTM and BiLSTM+ELMO on STS-B.