 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning on Monocular Videos for 3D Human Pose Estimation
Paper and Code
Dec 02, 2020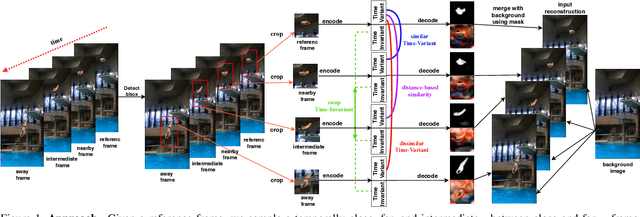
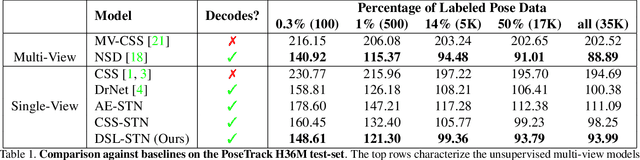
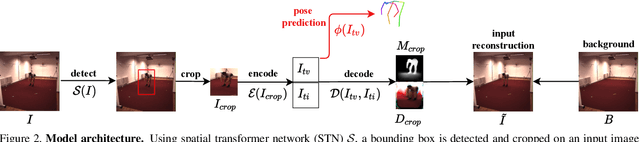
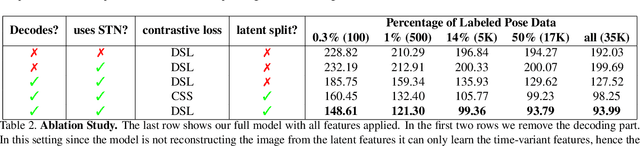
In this paper, we introduce an unsupervised feature extraction method that exploits contrastive self-supervised (CSS) learning to extract rich latent vectors from single-view videos. Instead of simply treating the latent features of nearby frames as positive pairs and those of temporally-distant ones as negative pairs as in other CSS approaches, we explicitly separate each latent vector into a time-variant component and a time-invariant one. We then show that applying CSS only to the time-variant features, while also reconstructing the input and encouraging a gradual transition between nearby and away features yields a rich latent space, well-suited for human pose estimation. Our approach outperforms other unsupervised single-view methods and match the performance of multi-view techniques.