 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deformable Registration for Multi-Modal Images via Disentangled Representations
Paper and Code
Mar 22, 2019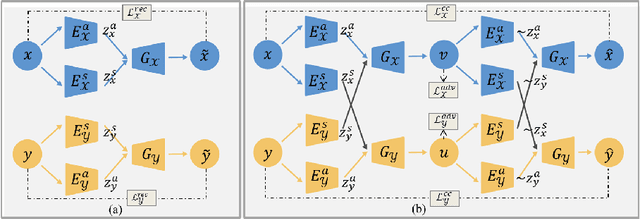
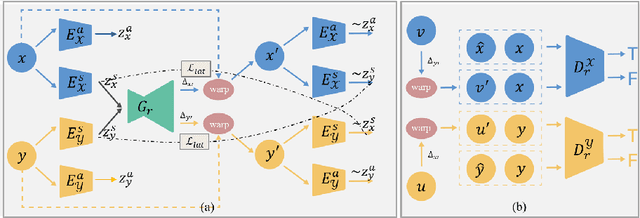
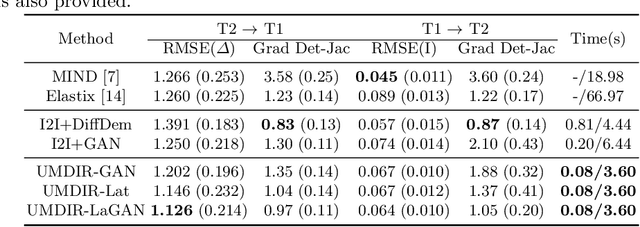
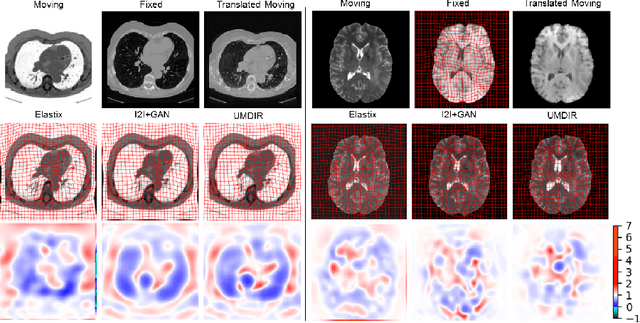
We propose a fully unsupervised multi-modal deformable image registration method (UMDIR), which does not require any ground truth deformation fields or any aligned multi-modal image pairs during training. Multi-modal registration is a key problem in many medical image analysis applications. It is very challenging due to complicated and unknown relationships between different modalities. In this paper, we propose an unsupervised learning approach to reduce the multi-modal registration problem to a mono-modal one through image disentangling. In particular, we decompose images of both modalities into a common latent shape space and separate latent appearance spaces via an unsupervised multi-modal image-to-image translation approach. The proposed registration approach is then built on the factorized latent shape code, with the assumption that the intrinsic shape deformation existing in original image domain is preserved in this latent space. Specifically, two metrics have been proposed for training the proposed network: a latent similarity metric defined in the common shape space and a learningbased image similarity metric based on an adversarial loss. We examined different variations of our proposed approach and compared them with conventional state-of-the-art multi-modal registration methods. Results show that our proposed methods achieve competitive performance against other methods at substantially reduced computation time.