 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Metric Learning via Orthogonality based Probabilistic Loss
Paper and Code
Aug 22, 2020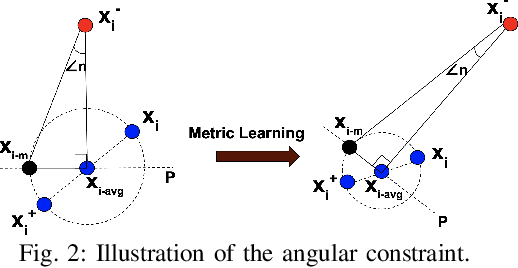

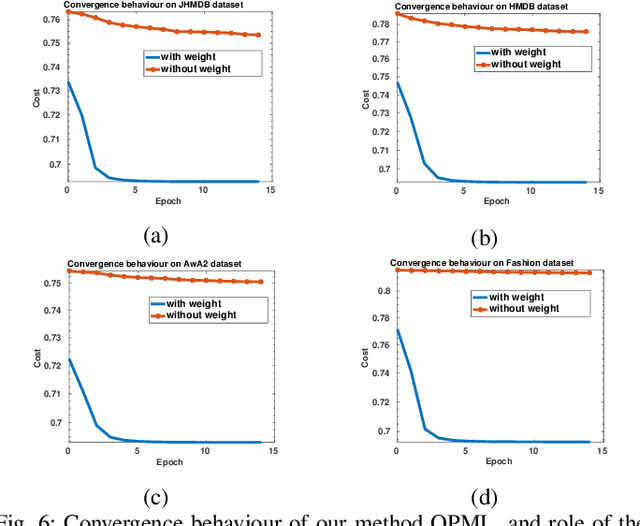
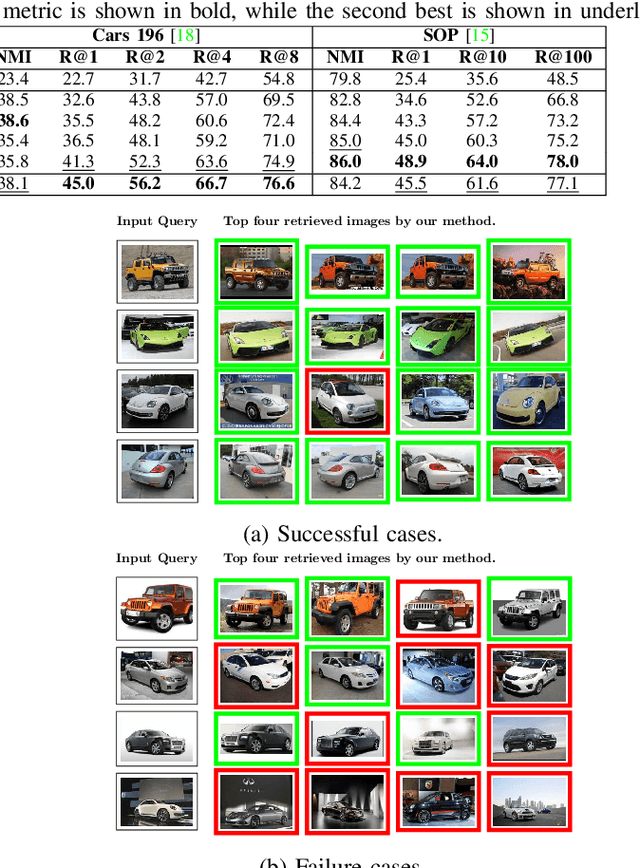
Metric learning is an important problem in machine learning. It aims to group similar examples together. Existing state-of-the-art metric learning approaches require class labels to learn a metric. As obtaining class labels in all applications is not feasible, we propose an unsupervised approach that learns a metric without making use of class labels. The lack of class labels is compensated by obtaining pseudo-labels of data using a graph-based clustering approach. The pseudo-labels are used to form triplets of examples, which guide the metric learning. We propose a probabilistic loss that minimizes the chances of each triplet violating an angular constraint. A weight function, and an orthogonality constraint in the objective speeds up the convergence and avoids a model collapse. We also provide a stochastic formulation of our method to scale up to large-scale datasets. Our studies demonstrate the competitiveness of our approach against state-of-the-art methods. We also thoroughly study the effect of the different components of our method.