 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNO: Uncertainty-aware Noisy-Or Multimodal Fusion for Unanticipated Input Degradation
Paper and Code
Nov 06, 2019

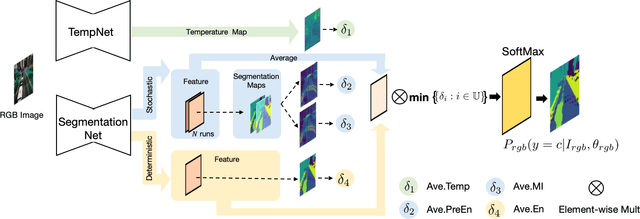
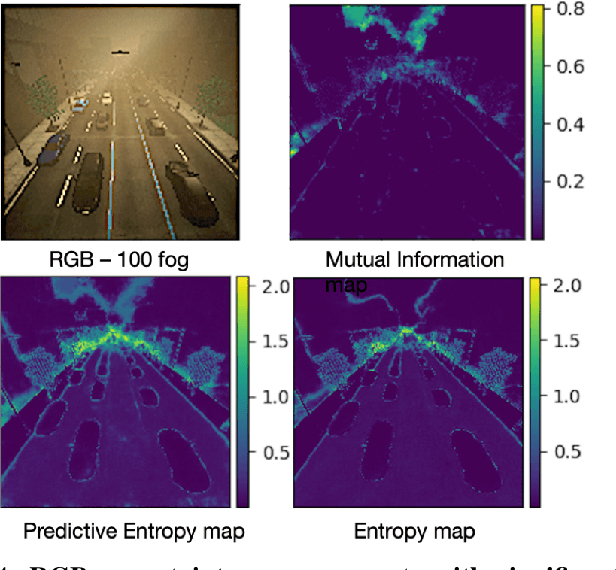
The fusion of multiple sensor modalities, especially through deep learning architectures, has been an active area of study. However, an under-explored aspect of such work is whether the methods can be robust to degradations across their input modalities, especially when they must generalize to degradations not seen during training. In this work, we propose an uncertainty-aware fusion scheme to effectively fuse inputs that might suffer from a range of known and unknown degradations. Specifically, we analyze a number of uncertainty measures, each of which captures a different aspect of uncertainty, and we propose a novel way to fuse degraded inputs by scaling modality-specific output softmax probabilities. We additionally propose a novel data-dependent spatial temperature scaling method to complement these existing uncertainty measures. Finally, we integrate the uncertainty-scaled output from each modality using a probabilistic noisy-or fusion method. In a photo-realistic simulation environment (AirSim), we show that our method achieves significantly better results on a semantic segmentation task, compared to state-of-art fusion architectures, on a range of degradations (e.g. fog, snow, frost, and various other types of noise), some of which are unknown during training. We specifically improve upon the state-of-art[1] by 28% in mean IoU on various degradations. [1] Abhinav Valada, Rohit Mohan, and Wolfram Burgard. Self-Supervised Model Adaptation for Multimodal Semantic Segmentation. In: arXiv e-prints, arXiv:1808.03833 (Aug. 2018), arXiv:1808.03833. arXiv: 1808.03833 [cs.CV].