 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Vision-Language Pre-Training for Image Captioning and VQA
Paper and Code



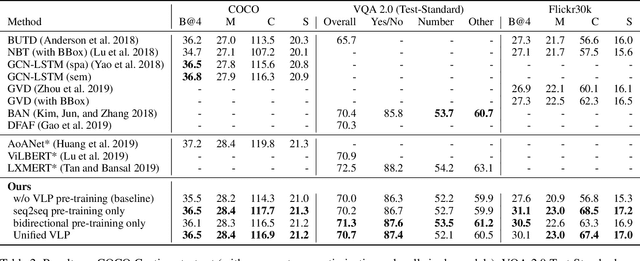
This paper presents a unified Vision-Language Pre-training (VLP) model. The model is unified in that (1) it can be fine-tuned for either vision-language generation (e.g., image captioning) or understanding (e.g., visual question answering) tasks, and (2) it uses a shared multi-layer transformer network for both encoding and decoding, which differs from many existing methods where the encoder and decoder are implemented using separate models. The unified VLP model is pre-trained on a large amount of image-text pairs using the unsupervised learning objectives of two tasks: bidirectional and sequence-to-sequence (seq2seq) masked vision-language prediction. The two tasks differ solely in what context the prediction conditions on. This is controlled by utilizing specific self-attention masks for the shared transformer network. To the best of our knowledge, VLP is the first reported model that achieves state-of-the-art results on both vision-language generation and understanding tasks, as disparate as image captioning and visual question answering, across three challenging benchmark datasets: COCO Captions, Flickr30k Captions, and VQA 2.0. The code and the pre-trained models are available at https://github.com/LuoweiZhou/VLP.