 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Policy Optimization for Continuous-action Reinforcement Learning in Non-stationary Tasks and Games
Paper and Code
Aug 19, 2022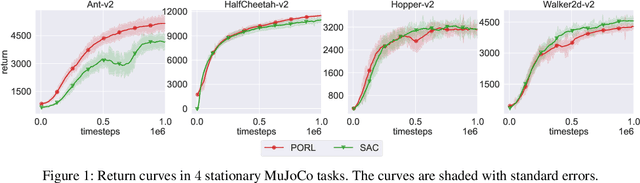

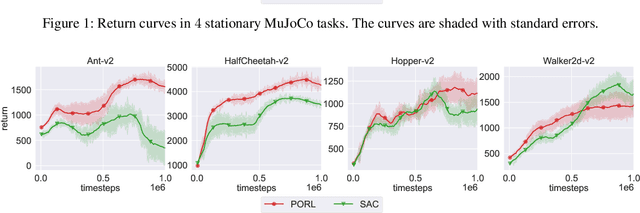

This paper addresses policy learning in non-stationary environments and games with continuous actions. Rather than the classical reward maximization mechanism, inspired by the ideas of follow-the-regularized-leader (FTRL) and mirror descent (MD) update, we propose a no-regret style reinforcement learning algorithm PORL for continuous action tasks. We prove that PORL has a last-iterate convergence guarantee, which is important for adversarial and cooperative games. Empirical studies show that, in stationary environments such as MuJoCo locomotion controlling tasks, PORL performs equally well as, if not better than, the soft actor-critic (SAC) algorithm; in non-stationary environments including dynamical environments, adversarial training, and competitive games, PORL is superior to SAC in both a better final policy performance and a more stable training process.