 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Downstream Instability of Word Embeddings
Paper and Code
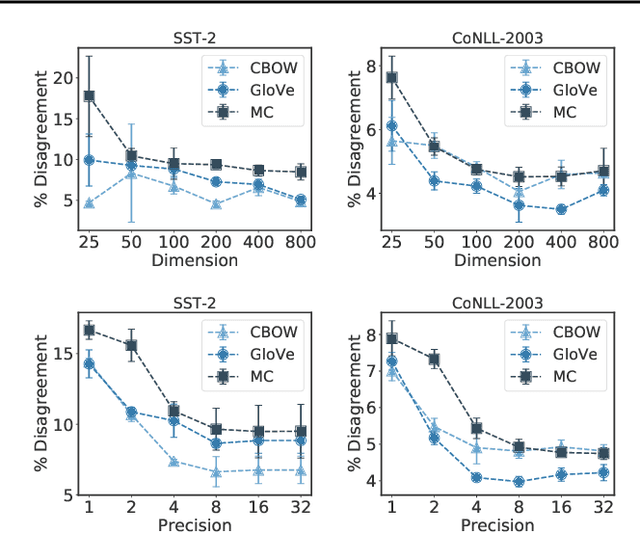

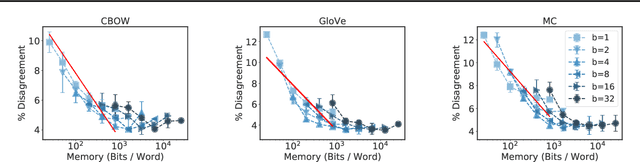
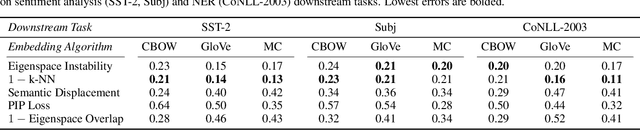
Many industrial machine learning (ML) systems require frequent retraining to keep up-to-date with constantly changing data. This retraining exacerbates a large challenge facing ML systems today: model training is unstable, i.e., small changes in training data can cause significant changes in the model's predictions. In this paper, we work on developing a deeper understanding of this instability, with a focus on how a core building block of modern natural language processing (NLP) pipelines---pre-trained word embeddings---affects the instability of downstream NLP models. We first empirically reveal a tradeoff between stability and memory: increasing the embedding memory 2x can reduce the disagreement in predictions due to small changes in training data by 5% to 37% (relative). To theoretically explain this tradeoff, we introduce a new measure of embedding instability---the eigenspace instability measure---which we prove bounds the disagreement in downstream predictions introduced by the change in word embeddings. Practically, we show that the eigenspace instability measure can be a cost-effective way to choose embedding parameters to minimize instability without training downstream models, outperforming other embedding distance measures and performing competitively with a nearest neighbor-based measure. Finally, we demonstrate that the observed stability-memory tradeoffs extend to other types of embeddings as well, including knowledge graph and contextual word embeddings.