 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Misclassifications by Attributes
Paper and Code
Oct 15, 2019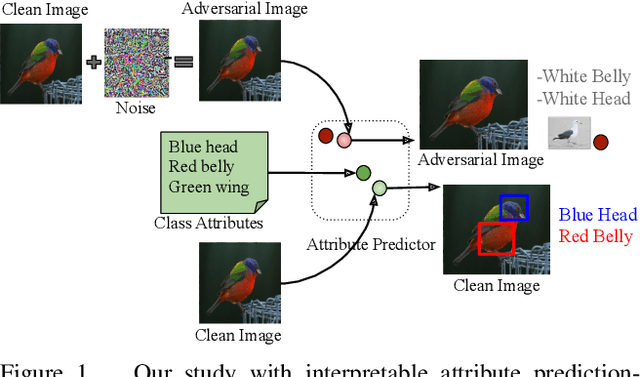
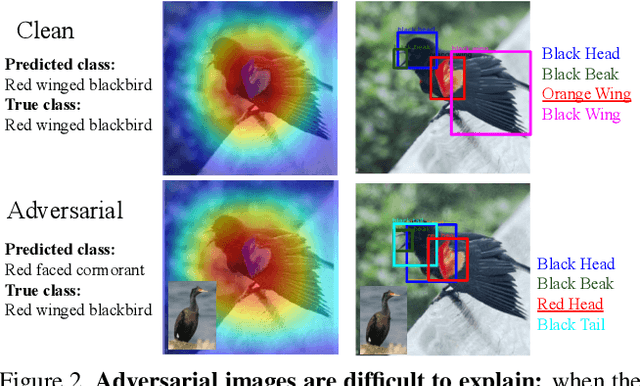
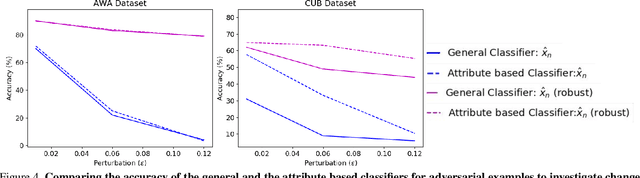
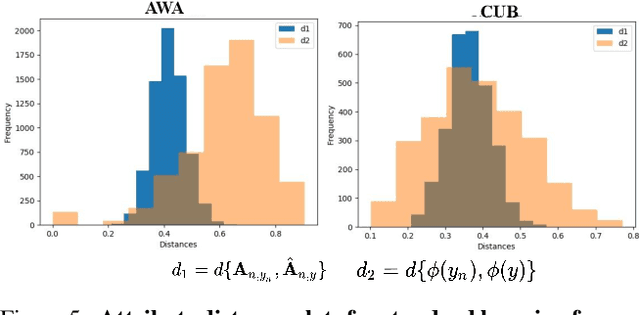
In this paper, we aim to understand and explain the decisions of deep neural networks by studying the behavior of predicted attributes when adversarial examples are introduced. We study the changes in attributes for clean as well as adversarial images in both standard and adversarially robust networks. We propose a metric to quantify the robustness of an adversarially robust network against adversarial attacks. In a standard network, attributes predicted for adversarial images are consistent with the wrong class, while attributes predicted for the clean images are consistent with the true class. In an adversarially robust network, the attributes predicted for adversarial images classified correctly are consistent with the true class. Finally, we show that the ability to robustify a network varies for different datasets. For the fine grained dataset, it is higher as compared to the coarse-grained dataset. Additionally, the ability to robustify a network increases with the increase in adversarial noise.