 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Gradient Descent on Edge of Stability in Deep Learning
Paper and Code
May 19, 2022
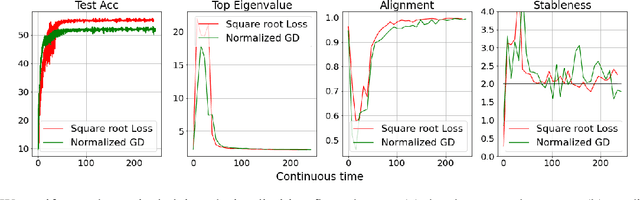

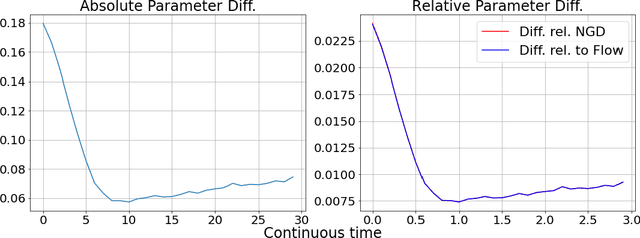
Deep learning experiments in Cohen et al. (2021) using deterministic Gradient Descent (GD) revealed an {\em Edge of Stability (EoS)} phase when learning rate (LR) and sharpness (\emph{i.e.}, the largest eigenvalue of Hessian) no longer behave as in traditional optimization. Sharpness stabilizes around $2/$LR and loss goes up and down across iterations, yet still with an overall downward trend. The current paper mathematically analyzes a new mechanism of implicit regularization in the EoS phase, whereby GD updates due to non-smooth loss landscape turn out to evolve along some deterministic flow on the manifold of minimum loss. This is in contrast to many previous results about implicit bias either relying on infinitesimal updates or noise in gradient. Formally, for any smooth function $L$ with certain regularity condition, this effect is demonstrated for (1) {\em Normalized GD}, i.e., GD with a varying LR $ \eta_t =\frac{ \eta }{ || \nabla L(x(t)) || } $ and loss $L$; (2) GD with constant LR and loss $\sqrt{L}$. Both provably enter the Edge of Stability, with the associated flow on the manifold minimizing $\lambda_{\max}(\nabla^2 L)$. The above theoretical results have been corroborated by an experimental study.