 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Scene Graph Generation via Rich and Fair Semantic Extraction
Paper and Code
Feb 01, 2020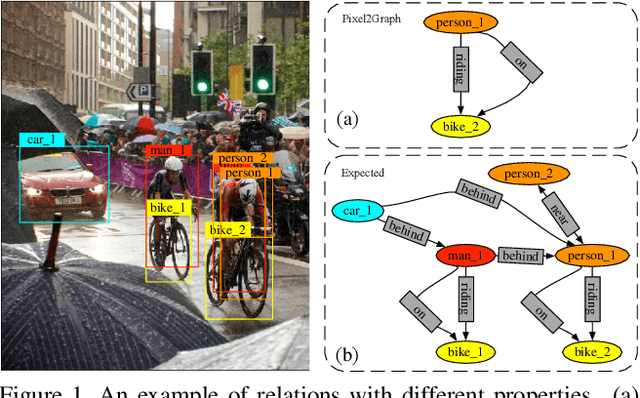



Extracting graph representation of visual scenes in image is a challenging task in computer vision. Although there has been encouraging progress of scene graph generation in the past decade, we surprisingly find that the performance of existing approaches is largely limited by the strong biases, which mainly stem from (1) unconsciously assuming relations with certain semantic properties such as symmetric and (2) imbalanced annotations over different relations. To alleviate the negative effects of these biases, we proposed a new and simple architecture named Rich and Fair semantic extraction network (RiFa for short), to not only capture rich semantic properties of the relations, but also fairly predict relations with different scale of annotations. Using pseudo-siamese networks, RiFa embeds the subject and object respectively to distinguish their semantic differences and meanwhile preserve their underlying semantic properties. Then, it further predicts subject-object relations based on both the visual and semantic features of entities under certain contextual area, and fairly ranks the relation predictions for those with a few annotations. Experiments on the popular Visual Genome dataset show that RiFa achieves state-of-the-art performance under several challenging settings of scene graph task. Especially, it performs significantly better on capturing different semantic properties of relations, and obtains the best overall per relation performance.