 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO-BLO: Unbiased First-Order Bilevel Optimization
Paper and Code
Jun 05, 2020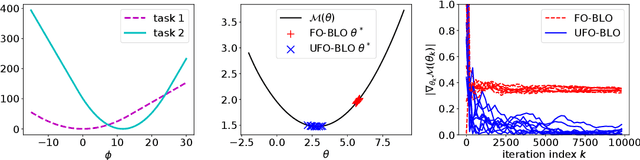



Bilevel optimization (BLO) is a popular approach with many applications including hyperparameter optimization, neural architecture search, adversarial robustness and model-agnostic meta-learning. However, the approach suffers from time and memory complexity proportional to the length $r$ of its inner optimization loop, which has led to several modifications being proposed. One such modification is \textit{first-order} BLO (FO-BLO) which approximates outer-level gradients by zeroing out second derivative terms, yielding significant speed gains and requiring only constant memory as $r$ varies. Despite FO-BLO's popularity, there is a lack of theoretical understanding of its convergence properties. We make progress by demonstrating a rich family of examples where FO-BLO-based stochastic optimization does not converge to a stationary point of the BLO objective. We address this concern by proposing a new FO-BLO-based unbiased estimate of outer-level gradients, enabling us to theoretically guarantee this convergence, with no harm to memory and expected time complexity. Our findings are supported by experimental results on Omniglot and Mini-ImageNet, popular few-shot meta-learning benchmarks.