 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-shaped Transformer with Frequency-Band Aware Attention for Speech Enhancement
Paper and Code
Dec 11, 2021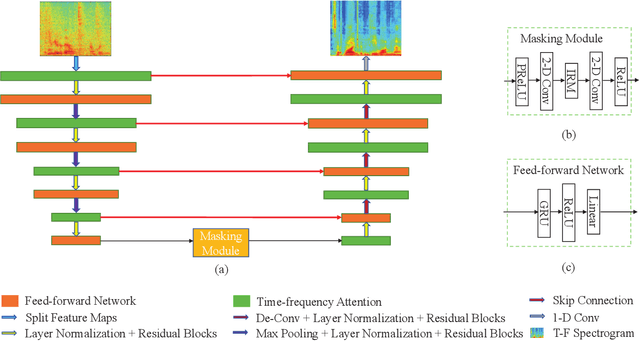

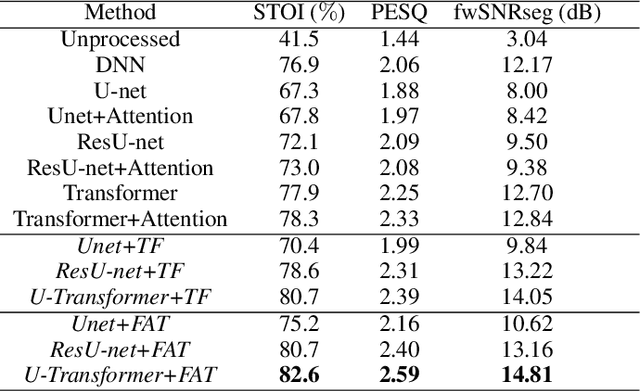
The state-of-the-art speech enhancement has limited performance in speech estimation accuracy. Recently, in deep learning, the Transformer shows the potential to exploit the long-range dependency in speech by self-attention. Therefore, it is introduced in speech enhancement to improve the speech estimation accuracy from a noise mixture. However, to address the computational cost issue in Transformer with self-attention, the axial attention is the option i.e., to split a 2D attention into two 1D attentions. Inspired by the axial attention, in the proposed method we calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps. Moreover, different from the axial attention, the proposed method provides two parallel multi-head attentions for time- and frequency-axis. Furthermore, it is proven in the literature that the lower frequency-band in speech, generally, contains more desired information than the higher frequency-band, in a noise mixture. Therefore, the frequency-band aware attention is proposed i.e., high frequency-band attention (HFA), and low frequency-band attention (LFA). The U-shaped Transformer is also first time introduced in the proposed method to further improve the speech estimation accuracy. The extensive evaluations over four public datasets, confirm the efficacy of the proposed method.