 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Best-scored Random Forest for Large-scale Regression
Paper and Code
May 09, 2019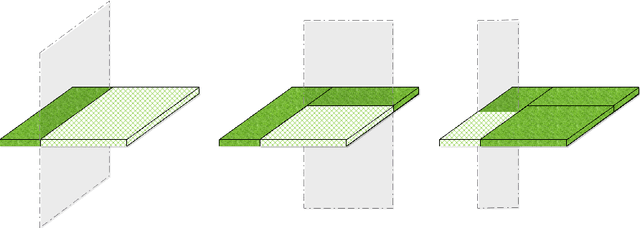
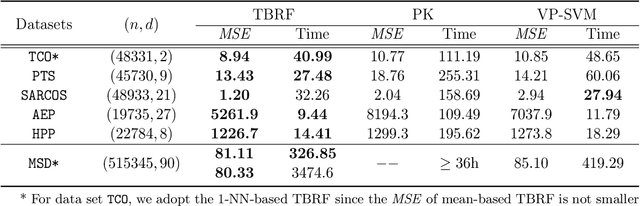

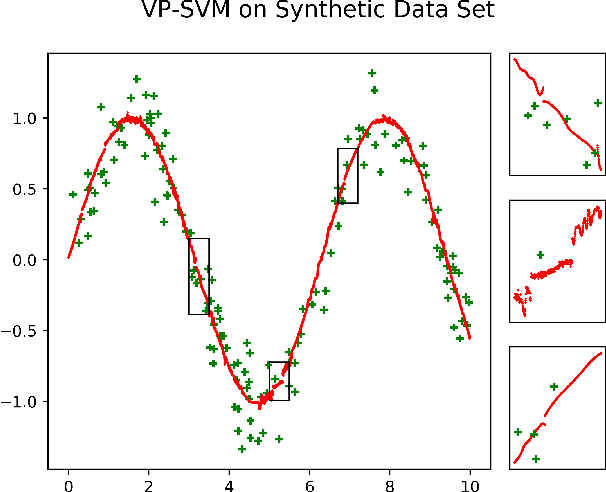
We propose a novel method designed for large-scale regression problems, namely the two-stage best-scored random forest (TBRF). "Best-scored" means to select one regression tree with the best empirical performance out of a certain number of purely random regression tree candidates, and "two-stage" means to divide the original random tree splitting procedure into two: In stage one, the feature space is partitioned into non-overlapping cells; in stage two, child trees grow separately on these cells. The strengths of this algorithm can be summarized as follows: First of all, the pure randomness in TBRF leads to the almost optimal learning rates, and also makes ensemble learning possible, which resolves the boundary discontinuities long plaguing the existing algorithms. Secondly, the two-stage procedure paves the way for parallel computing, leading to computational efficiency. Last but not least, TBRF can serve as an inclusive framework where different mainstream regression strategies such as linear predictor and least squares support vector machines (LS-SVMs) can also be incorporated as value assignment approaches on leaves of the child trees, depending on the characteristics of the underlying data sets. Numerical assessments on comparisons with other state-of-the-art methods on several large-scale real data sets validate the promising prediction accuracy and high computational efficiency of our algorithm.