 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo new algorithms for maximum likelihood estimation of sparse covariance matrices with applications to graphical modeling
Paper and Code
May 11, 2023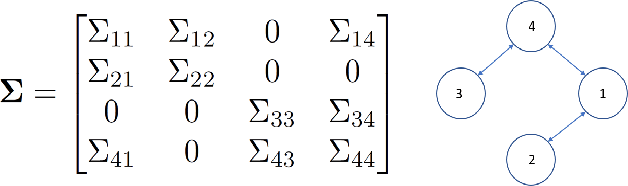
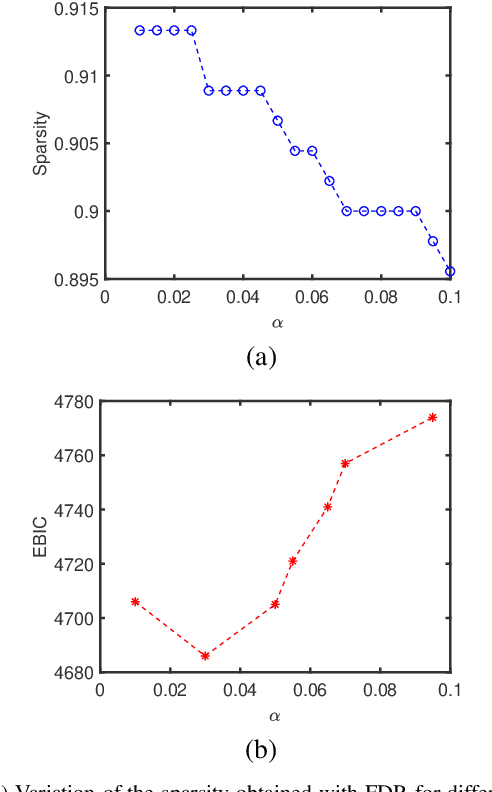
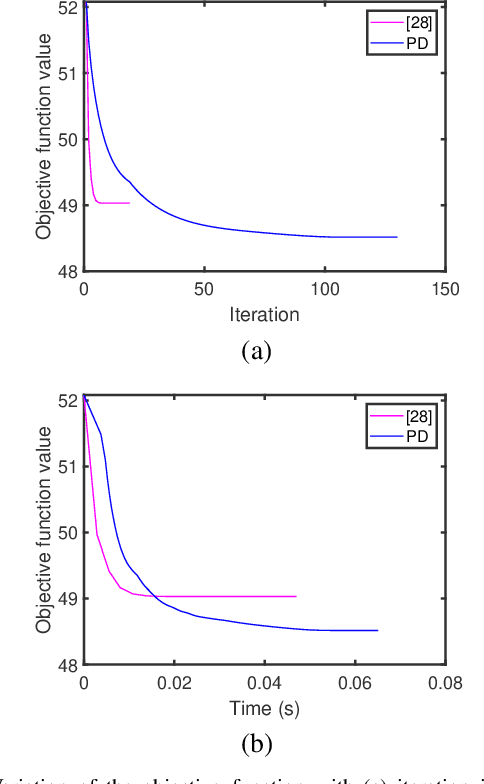
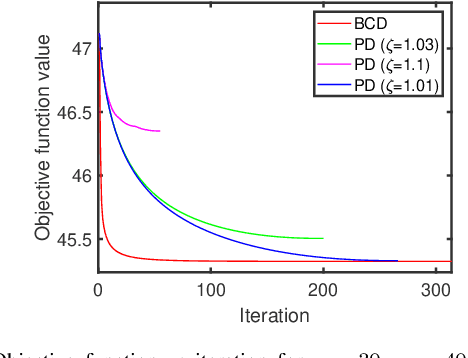
In this paper, we propose two new algorithms for maximum-likelihood estimation (MLE) of high dimensional sparse covariance matrices. Unlike most of the state of-the-art methods, which either use regularization techniques or penalize the likelihood to impose sparsity, we solve the MLE problem based on an estimated covariance graph. More specifically, we propose a two-stage procedure: in the first stage, we determine the sparsity pattern of the target covariance matrix (in other words the marginal independence in the covariance graph under a Gaussian graphical model) using the multiple hypothesis testing method of false discovery rate (FDR), and in the second stage we use either a block coordinate descent approach to estimate the non-zero values or a proximal distance approach that penalizes the distance between the estimated covariance graph and the target covariance matrix. Doing so gives rise to two different methods, each with its own advantage: the coordinate descent approach does not require tuning of any hyper-parameters, whereas the proximal distance approach is computationally fast but requires a careful tuning of the penalty parameter. Both methods are effective even in cases where the number of observed samples is less than the dimension of the data. For performance evaluation, we test the proposed methods on both simulated and real-world data and show that they provide more accurate estimates of the sparse covariance matrix than two state-of-the-art methods.