 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripleSpin - a generic compact paradigm for fast machine learning computations
Paper and Code
Jun 06, 2016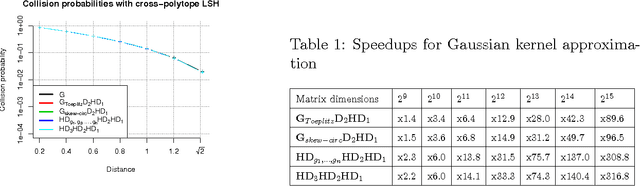
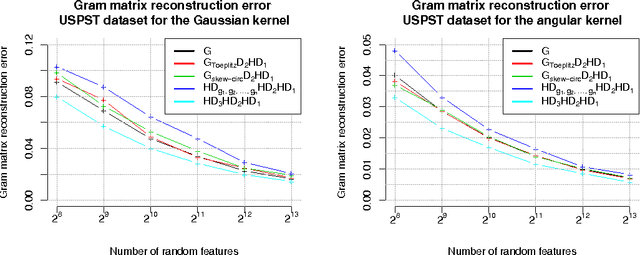
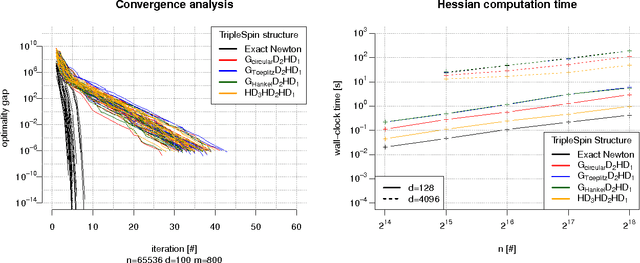
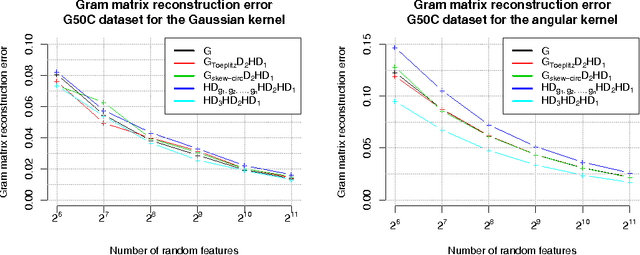
We present a generic compact computational framework relying on structured random matrices that can be applied to speed up several machine learning algorithms with almost no loss of accuracy. The applications include new fast LSH-based algorithms, efficient kernel computations via random feature maps, convex optimization algorithms, quantization techniques and many more. Certain models of the presented paradigm are even more compressible since they apply only bit matrices. This makes them suitable for deploying on mobile devices. All our findings come with strong theoretical guarantees. In particular, as a byproduct of the presented techniques and by using relatively new Berry-Esseen-type CLT for random vectors, we give the first theoretical guarantees for one of the most efficient existing LSH algorithms based on the $\textbf{HD}_{3}\textbf{HD}_{2}\textbf{HD}_{1}$ structured matrix ("Practical and Optimal LSH for Angular Distance"). These guarantees as well as theoretical results for other aforementioned applications follow from the same general theoretical principle that we present in the paper. Our structured family contains as special cases all previously considered structured schemes, including the recently introduced $P$-model. Experimental evaluation confirms the accuracy and efficiency of TripleSpin matrices.