 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrees in transformers: a theoretical analysis of the Transformer's ability to represent trees
Paper and Code
Dec 16, 2021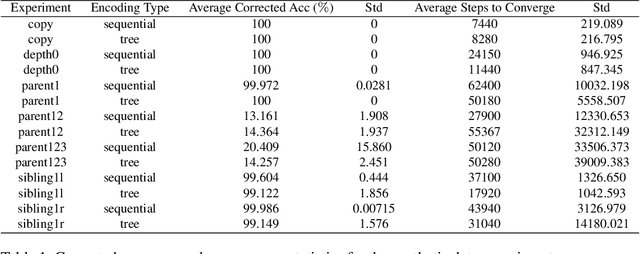
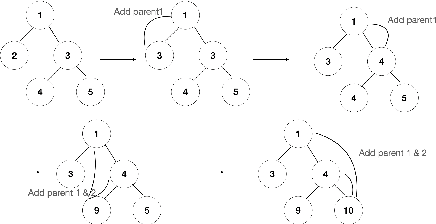
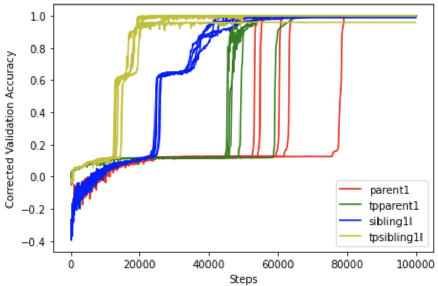
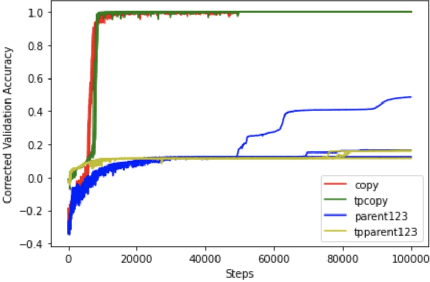
Transformer networks are the de facto standard architecture in natural language processing. To date, there are no theoretical analyses of the Transformer's ability to capture tree structures. We focus on the ability of Transformer networks to learn tree structures that are important for tree transduction problems. We first analyze the theoretical capability of the standard Transformer architecture to learn tree structures given enumeration of all possible tree backbones, which we define as trees without labels. We then prove that two linear layers with ReLU activation function can recover any tree backbone from any two nonzero, linearly independent starting backbones. This implies that a Transformer can learn tree structures well in theory. We conduct experiments with synthetic data and find that the standard Transformer achieves similar accuracy compared to a Transformer where tree position information is explicitly encoded, albeit with slower convergence. This confirms empirically that Transformers can learn tree structures.