 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransLoc3D : Point Cloud based Large-scale Place Recognition using Adaptive Receptive Fields
Paper and Code
Jun 01, 2021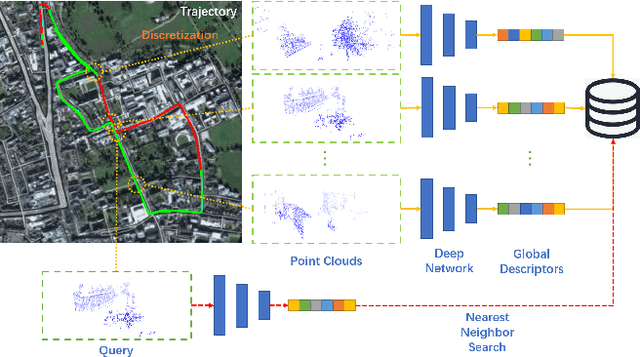
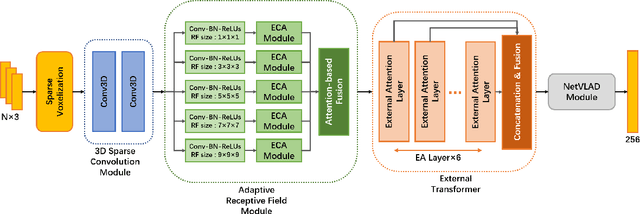
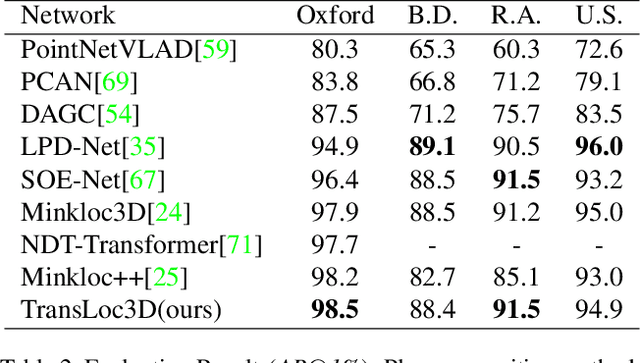
Place recognition plays an essential role in the field of autonomous driving and robot navigation. Although a number of point cloud based methods have been proposed and achieved promising results, few of them take the size difference of objects into consideration. For small objects like pedestrians and vehicles, large receptive fields will capture unrelated information, while small receptive fields would fail to encode complete geometric information for large objects such as buildings. We argue that fixed receptive fields are not well suited for place recognition, and propose a novel Adaptive Receptive Field Module (ARFM), which can adaptively adjust the size of the receptive field based on the input point cloud. We also present a novel network architecture, named TransLoc3D, to obtain discriminative global descriptors of point clouds for the place recognition task. TransLoc3D consists of a 3D sparse convolutional module, an ARFM module, an external transformer network which aims to capture long range dependency and a NetVLAD layer. Experiments show that our method outperforms prior state-of-the-art results, with an improvement of 1.1\% on average recall@1 on the Oxford RobotCar dataset, and 0.8\% on the B.D. dataset.