 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation between Molecules and Natural Language
Paper and Code
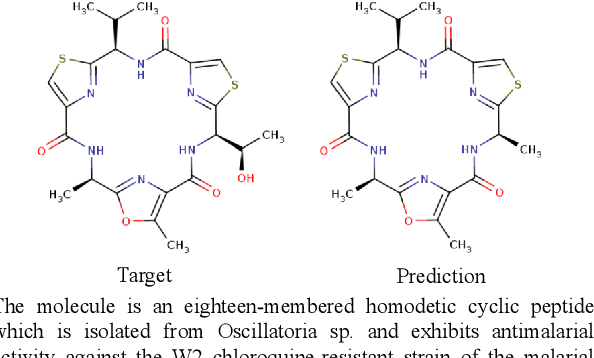
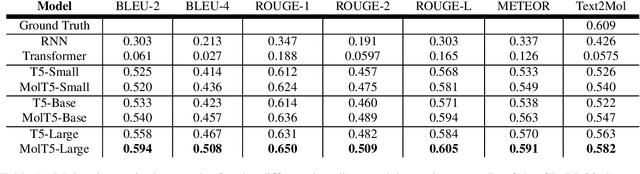
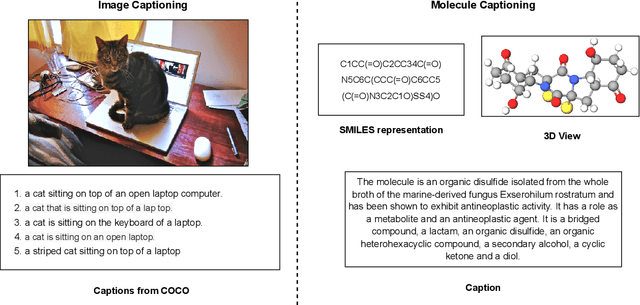
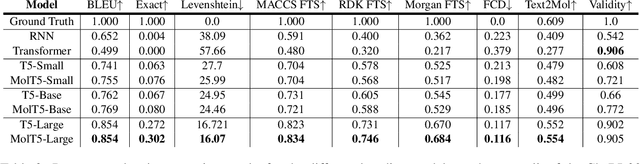
Joint representations between images and text have been deeply investigated in the literature. In computer vision, the benefits of incorporating natural language have become clear for enabling semantic-level control of images. In this work, we present $\textbf{MolT5}-$a self-supervised learning framework for pretraining models on a vast amount of unlabeled natural language text and molecule strings. $\textbf{MolT5}$ allows for new, useful, and challenging analogs of traditional vision-language tasks, such as molecule captioning and text-based de novo molecule generation (altogether: translation between molecules and language), which we explore for the first time. Furthermore, since $\textbf{MolT5}$ pretrains models on single-modal data, it helps overcome the chemistry domain shortcoming of data scarcity. Additionally, we consider several metrics, including a new cross-modal embedding-based metric, to evaluate the tasks of molecule captioning and text-based molecule generation. By interfacing molecules with natural language, we enable a higher semantic level of control over molecule discovery and understanding--a critical task for scientific domains such as drug discovery and material design. Our results show that $\textbf{MolT5}$-based models are able to generate outputs, both molecule and text, which in many cases are high quality and match the input modality. On molecule generation, our best model achieves 30% exact matching test accuracy (i.e., it generates the correct structure for about one-third of the captions in our held-out test set).